- Current Team
- Funded Projects

Selected Research Projects
- COVID-19 Response
- Articles in Peer-reviewed Journals
- Articles in Books and Proceedings
- Edited Books
- Presentations
Dissertations & Theses
- Lab Resources
- Place Connectivity Index
- Human Mobility Flows
- Twitter Census
Ph.D. Dissertations
Qian Huang (2022), Spatial and Age Disparities in COVID-19 Outcomes (Committee: Drs. Susan Cutter, Zhenlong Li, Kevin Bennett, Jan Eberth, Jerry Mitchell)
Grayson Morgan (2022), sUAS and Deep Learning for High-resolution Monitoring of Tidal Marshes in Coastal South Carolina , (Committee: Drs. Susan Wang, Zhenlong Li, Michael Hodgson, Steve Schill )
Jiang Y. (2022), Quantifying Human Mobility Patterns During Disruptive Events with Big Data (Committee: Drs. Zhenlong Li, Susan Cutter, Michael Hodgson, Qunying Huang )
Huang, X. (2020), Remote Sensing and Social Sensing for Improved Flood Awareness and Exposure Analysis in the Big Data Era (Committee: Drs. Susan Wang, Zhenlong Li, Michael Hodgson, David Hitchcock)
Derakhshan, S. (2020) Spatio-Temporal Modeling of Earthquake Recovery (Committee: Drs. Susan Cutter, Cuizhen Wang, Zhenlong Li, Melanie Gall)
Martin, Y. (2019), Leveraging Geotagged Social Media to Monitor Spatial Behavior During Population Movements Triggered by Hurricanes (Committee: Drs. Susan L. Cutter, Zhenlong Li, Jerry T. Mitchell, Christopher T. Emrich)
Master Theses
Fulham A. (2023). Sentiment analysis of Swedish and Finnish twitter users’ views toward NATO pre- and post- 2022 2nd Russian invasion of Ukraine (Committee: Drs. Zhenlong Li, Carl Dahlman, Robert Kopack)
Ning H. (2019). Prototyping A Social Media Flooding Photo Screening System Based On Deep Learning and Crowdsourcing (Committee: Drs. Zhenlong Li, Michael E. Hodgson, Cuizhen Wang)
Vayansky, I. R. (2018). An Evaluation of Geotagged Twitter Data during Hurricane Irma using Sentiment Analysis and Topic Modeling for Disaster Resilience. (Committee: Drs. Sathish A.P Kumar, Zhenlong Li, William Jones )
Pham. E. (2018). Analysis of Evacuation Behaviors and Departure Timing for October 2016’s Hurricane Matthew. (Committee: Drs. Susan L. Cutter, Christopher Emrich, Zhenlong Li )
Campbell. R. (2018). Tweets About Tornado Warnings: A Spatiotemporal & Content Analysis (Committee: Drs. Susan L. Cutter, Zhenlong Li, Gregory Carbone)
Windsor M. (2017). A Web-based Decision Support Platform for Community Engagement in Water Resources Planning (Committee: Drs. Zhenlong Li, Jean Taylor Ellis)
Jiang Y. (2016). Urban Accessibility Measurement and Visualization—A Big Data Approach (Committee: Drs. Diansheng Guo, Zhenlong Li, Michael E. Hodgson)
Undergraduate Theses (Honors and Graduate with Distinction)
Finn Hagerty (2021), Tracking Population Movement using Geotagged Tweets to and from New York City and Los Angeles during the COVID-19 Pandemic , (Committee: Drs. Zhenlong Li, Amir Karami)
Murph R. (2019), Steering Clear of Single-Occupancy Vehicles: Campus Transportation Demand Management Strategies for the University of South Carolina (Committee: Drs. Conor M. Harrison, Zhenlong Li)
- How our collective efforts of fighting the virus are reflected on maps?
- ODT Flow Explorer: Extract, Query, and Visualize Human Mobility
- Human Mobility, Policy, and COVID-19: A Preliminary Analysis of South Carolina
- Big Geo-tweets Computing
- Social Sensing and Big Data Computing for Evacuation Analysis
- Social Sensing and Big Data Computing for Rapid Flood Mapping
- Spatiotemporal Indexing Approach (SIA) for efficient management, access, and analyze Big Climate and Remote Sensing Data
- Spatiotemporal query analytics for parallel climate data aggregation and analysis
- SOVAS: A Scalable Online Visual Analytic System for Big Climate Data Analysis
- Human mobility during disruptive events
- Measuring and modeling activity space
- Understanding tourist movement patterns with big data
- Exploring the vertical dimension of street view image: lowest floor elevation estimation
- Sidewalk Extraction from Big Visual Data
- Warning : Invalid argument supplied for foreach() in /home/customer/www/opendatascience.com/public_html/wp-includes/nav-menu.php on line 95 Warning : array_merge(): Expected parameter 2 to be an array, null given in /home/customer/www/opendatascience.com/public_html/wp-includes/nav-menu.php on line 102
- ODSC EUROPE
- AI+ Training
- Speak at ODSC

- Data Analytics
- Data Engineering
- Data Visualization
- Deep Learning
- Generative AI
- Machine Learning
- NLP and LLMs
- Business & Use Cases
- Career Advice
- Write for us
- ODSC Community Slack Channel
- Upcoming Webinars

17 Compelling Machine Learning Ph.D. Dissertations
Machine Learning Modeling Research posted by Daniel Gutierrez, ODSC August 12, 2021 Daniel Gutierrez, ODSC
Working in the field of data science, I’m always seeking ways to keep current in the field and there are a number of important resources available for this purpose: new book titles, blog articles, conference sessions, Meetups, webinars/podcasts, not to mention the gems floating around in social media. But to dig even deeper, I routinely look at what’s coming out of the world’s research labs. And one great way to keep a pulse for what the research community is working on is to monitor the flow of new machine learning Ph.D. dissertations. Admittedly, many such theses are laser-focused and narrow, but from previous experience reading these documents, you can learn an awful lot about new ways to solve difficult problems over a vast range of problem domains.
In this article, I present a number of hand-picked machine learning dissertations that I found compelling in terms of my own areas of interest and aligned with problems that I’m working on. I hope you’ll find a number of them that match your own interests. Each dissertation may be challenging to consume but the process will result in hours of satisfying summer reading. Enjoy!
Please check out my previous data science dissertation round-up article .
1. Fitting Convex Sets to Data: Algorithms and Applications
This machine learning dissertation concerns the geometric problem of finding a convex set that best fits a given data set. The overarching question serves as an abstraction for data-analytical tasks arising in a range of scientific and engineering applications with a focus on two specific instances: (i) a key challenge that arises in solving inverse problems is ill-posedness due to a lack of measurements. A prominent family of methods for addressing such issues is based on augmenting optimization-based approaches with a convex penalty function so as to induce a desired structure in the solution. These functions are typically chosen using prior knowledge about the data. The thesis also studies the problem of learning convex penalty functions directly from data for settings in which we lack the domain expertise to choose a penalty function. The solution relies on suitably transforming the problem of learning a penalty function into a fitting task; and (ii) the problem of fitting tractably-described convex sets given the optimal value of linear functionals evaluated in different directions.
2. Structured Tensors and the Geometry of Data
This machine learning dissertation analyzes data to build a quantitative understanding of the world. Linear algebra is the foundation of algorithms, dating back one hundred years, for extracting structure from data. Modern technologies provide an abundance of multi-dimensional data, in which multiple variables or factors can be compared simultaneously. To organize and analyze such data sets we can use a tensor , the higher-order analogue of a matrix. However, many theoretical and practical challenges arise in extending linear algebra to the setting of tensors. The first part of the thesis studies and develops the algebraic theory of tensors. The second part of the thesis presents three algorithms for tensor data. The algorithms use algebraic and geometric structure to give guarantees of optimality.
3. Statistical approaches for spatial prediction and anomaly detection
This machine learning dissertation is primarily a description of three projects. It starts with a method for spatial prediction and parameter estimation for irregularly spaced, and non-Gaussian data. It is shown that by judiciously replacing the likelihood with an empirical likelihood in the Bayesian hierarchical model, approximate posterior distributions for the mean and covariance parameters can be obtained. Due to the complex nature of the hierarchical model, standard Markov chain Monte Carlo methods cannot be applied to sample from the posterior distributions. To overcome this issue, a generalized sequential Monte Carlo algorithm is used. Finally, this method is applied to iron concentrations in California. The second project focuses on anomaly detection for functional data; specifically for functional data where the observed functions may lie over different domains. By approximating each function as a low-rank sum of spline basis functions the coefficients will be compared for each basis across each function. The idea being, if two functions are similar then their respective coefficients should not be significantly different. This project concludes with an application of the proposed method to detect anomalous behavior of users of a supercomputer at NREL. The final project is an extension of the second project to two-dimensional data. This project aims to detect location and temporal anomalies from ground motion data from a fiber-optic cable using distributed acoustic sensing (DAS).
4. Sampling for Streaming Data
Advances in data acquisition technology pose challenges in analyzing large volumes of streaming data. Sampling is a natural yet powerful tool for analyzing such data sets due to their competent estimation accuracy and low computational cost. Unfortunately, sampling methods and their statistical properties for streaming data, especially streaming time series data, are not well studied in the literature. Meanwhile, estimating the dependence structure of multidimensional streaming time-series data in real-time is challenging. With large volumes of streaming data, the problem becomes more difficult when the multidimensional data are collected asynchronously across distributed nodes, which motivates us to sample representative data points from streams. This machine learning dissertation proposes a series of leverage score-based sampling methods for streaming time series data. The simulation studies and real data analysis are conducted to validate the proposed methods. The theoretical analysis of the asymptotic behaviors of the least-squares estimator is developed based on the subsamples.
5. Statistical Machine Learning Methods for Complex, Heterogeneous Data
This machine learning dissertation develops statistical machine learning methodology for three distinct tasks. Each method blends classical statistical approaches with machine learning methods to provide principled solutions to problems with complex, heterogeneous data sets. The first framework proposes two methods for high-dimensional shape-constrained regression and classification. These methods reshape pre-trained prediction rules to satisfy shape constraints like monotonicity and convexity. The second method provides a nonparametric approach to the econometric analysis of discrete choice. This method provides a scalable algorithm for estimating utility functions with random forests, and combines this with random effects to properly model preference heterogeneity. The final method draws inspiration from early work in statistical machine translation to construct embeddings for variable-length objects like mathematical equations
6. Topics in Multivariate Statistics with Dependent Data
This machine learning dissertation comprises four chapters. The first is an introduction to the topics of the dissertation and the remaining chapters contain the main results. Chapter 2 gives new results for consistency of maximum likelihood estimators with a focus on multivariate mixed models. The presented theory builds on the idea of using subsets of the full data to establish consistency of estimators based on the full data. The theory is applied to two multivariate mixed models for which it was unknown whether maximum likelihood estimators are consistent. In Chapter 3 an algorithm is proposed for maximum likelihood estimation of a covariance matrix when the corresponding correlation matrix can be written as the Kronecker product of two lower-dimensional correlation matrices. The proposed method is fully likelihood-based. Some desirable properties of separable correlation in comparison to separable covariance are also discussed. Chapter 4 is concerned with Bayesian vector auto-regressions (VARs). A collapsed Gibbs sampler is proposed for Bayesian VARs with predictors and the convergence properties of the algorithm are studied.
7. Model Selection and Estimation for High-dimensional Data Analysis
In the era of big data, uncovering useful information and hidden patterns in the data is prevalent in different fields. However, it is challenging to effectively select input variables in data and estimate their effects. The goal of this machine learning dissertation is to develop reproducible statistical approaches that provide mechanistic explanations of the phenomenon observed in big data analysis. The research contains two parts: variable selection and model estimation. The first part investigates how to measure and interpret the usefulness of an input variable using an approach called “variable importance learning” and builds tools (methodology and software) that can be widely applied. Two variable importance measures are proposed, a parametric measure SOIL and a non-parametric measure CVIL, using the idea of a model combining and cross-validation respectively. The SOIL method is theoretically shown to have the inclusion/exclusion property: When the model weights are properly around the true model, the SOIL importance can well separate the variables in the true model from the rest. The CVIL method possesses desirable theoretical properties and enhances the interpretability of many mysterious but effective machine learning methods. The second part focuses on how to estimate the effect of a useful input variable in the case where the interaction of two input variables exists. Investigated is the minimax rate of convergence for regression estimation in high-dimensional sparse linear models with two-way interactions, and construct an adaptive estimator that achieves the minimax rate of convergence regardless of the true heredity condition and the sparsity indices.

8. High-Dimensional Structured Regression Using Convex Optimization
While the term “Big Data” can have multiple meanings, this dissertation considers the type of data in which the number of features can be much greater than the number of observations (also known as high-dimensional data). High-dimensional data is abundant in contemporary scientific research due to the rapid advances in new data-measurement technologies and computing power. Recent advances in statistics have witnessed great development in the field of high-dimensional data analysis. This machine learning dissertation proposes three methods that study three different components of a general framework of the high-dimensional structured regression problem. A general theme of the proposed methods is that they cast a certain structured regression as a convex optimization problem. In so doing, the theoretical properties of each method can be well studied, and efficient computation is facilitated. Each method is accompanied by a thorough theoretical analysis of its performance, and also by an R package containing its practical implementation. It is shown that the proposed methods perform favorably (both theoretically and practically) compared with pre-existing methods.
9. Asymptotics and Interpretability of Decision Trees and Decision Tree Ensembles
Decision trees and decision tree ensembles are widely used nonparametric statistical models. A decision tree is a binary tree that recursively segments the covariate space along the coordinate directions to create hyper rectangles as basic prediction units for fitting constant values within each of them. A decision tree ensemble combines multiple decision trees, either in parallel or in sequence, in order to increase model flexibility and accuracy, as well as to reduce prediction variance. Despite the fact that tree models have been extensively used in practice, results on their asymptotic behaviors are scarce. This machine learning dissertation presents analyses on tree asymptotics in the perspectives of tree terminal nodes, tree ensembles, and models incorporating tree ensembles respectively. The study introduces a few new tree-related learning frameworks which provides provable statistical guarantees and interpretations. A study on the Gini index used in the greedy tree building algorithm reveals its limiting distribution, leading to the development of a test of better splitting that helps to measure the uncertain optimality of a decision tree split. This test is combined with the concept of decision tree distillation, which implements a decision tree to mimic the behavior of a block box model, to generate stable interpretations by guaranteeing a unique distillation tree structure as long as there are sufficiently many random sample points. Also applied is mild modification and regularization to the standard tree boosting to create a new boosting framework named Boulevard. Also included is an integration of two new mechanisms: honest trees , which isolate the tree terminal values from the tree structure, and adaptive shrinkage , which scales the boosting history to create an equally weighted ensemble. This theoretical development provides the prerequisite for the practice of statistical inference with boosted trees. Lastly, the thesis investigates the feasibility of incorporating existing semi-parametric models with tree boosting.
10. Bayesian Models for Imputing Missing Data and Editing Erroneous Responses in Surveys
This dissertation develops Bayesian methods for handling unit nonresponse, item nonresponse, and erroneous responses in large-scale surveys and censuses containing categorical data. The focus is on applications of nested household data where individuals are nested within households and certain combinations of the variables are not allowed, such as the U.S. Decennial Census, as well as surveys subject to both unit and item nonresponse, such as the Current Population Survey.
11. Localized Variable Selection with Random Forest
Due to recent advances in computer technology, the cost of collecting and storing data has dropped drastically. This makes it feasible to collect large amounts of information for each data point. This increasing trend in feature dimensionality justifies the need for research on variable selection. Random forest (RF) has demonstrated the ability to select important variables and model complex data. However, simulations confirm that it fails in detecting less influential features in presence of variables with large impacts in some cases. This dissertation proposes two algorithms for localized variable selection: clustering-based feature selection (CBFS) and locally adjusted feature importance (LAFI). Both methods aim to find regions where the effects of weaker features can be isolated and measured. CBFS combines RF variable selection with a two-stage clustering method to detect variables where their effect can be detected only in certain regions. LAFI, on the other hand, uses a binary tree approach to split data into bins based on response variable rankings, and implements RF to find important variables in each bin. Larger LAFI is assigned to variables that get selected in more bins. Simulations and real data sets are used to evaluate these variable selection methods.
12. Functional Principal Component Analysis and Sparse Functional Regression
The focus of this dissertation is on functional data which are sparsely and irregularly observed. Such data require special consideration, as classical functional data methods and theory were developed for densely observed data. As is the case in much of functional data analysis, the functional principal components (FPCs) play a key role in current sparse functional data methods via the Karhunen-Loéve expansion. Thus, after a review of relevant background material, this dissertation is divided roughly into two parts, the first focusing specifically on theoretical properties of FPCs, and the second on regression for sparsely observed functional data.
13. Essays In Causal Inference: Addressing Bias In Observational And Randomized Studies Through Analysis And Design
In observational studies, identifying assumptions may fail, often quietly and without notice, leading to biased causal estimates. Although less of a concern in randomized trials where treatment is assigned at random, bias may still enter the equation through other means. This dissertation has three parts, each developing new methods to address a particular pattern or source of bias in the setting being studied. The first part extends the conventional sensitivity analysis methods for observational studies to better address patterns of heterogeneous confounding in matched-pair designs. The second part develops a modified difference-in-difference design for comparative interrupted time-series studies. The method permits partial identification of causal effects when the parallel trends assumption is violated by an interaction between group and history. The method is applied to a study of the repeal of Missouri’s permit-to-purchase handgun law and its effect on firearm homicide rates. The final part presents a study design to identify vaccine efficacy in randomized control trials when there is no gold standard case definition. The approach augments a two-arm randomized trial with natural variation of a genetic trait to produce a factorial experiment.
14. Bayesian Shrinkage: Computation, Methods, and Theory
Sparsity is a standard structural assumption that is made while modeling high-dimensional statistical parameters. This assumption essentially entails a lower-dimensional embedding of the high-dimensional parameter thus enabling sound statistical inference. Apart from this obvious statistical motivation, in many modern applications of statistics such as Genomics, Neuroscience, etc. parameters of interest are indeed of this nature. For over almost two decades, spike and slab type priors have been the Bayesian gold standard for modeling of sparsity. However, due to their computational bottlenecks, shrinkage priors have emerged as a powerful alternative. This family of priors can almost exclusively be represented as a scale mixture of Gaussian distribution and posterior Markov chain Monte Carlo (MCMC) updates of related parameters are then relatively easy to design. Although shrinkage priors were tipped as having computational scalability in high-dimensions, when the number of parameters is in thousands or more, they do come with their own computational challenges. Standard MCMC algorithms implementing shrinkage priors generally scale cubic in the dimension of the parameter making real-life application of these priors severely limited.
The first chapter of this dissertation addresses this computational issue and proposes an alternative exact posterior sampling algorithm complexity of which that linearly in the ambient dimension. The algorithm developed in the first chapter is specifically designed for regression problems. The second chapter develops a Bayesian method based on shrinkage priors for high-dimensional multiple response regression. Chapter three chooses a specific member of the shrinkage family known as the horseshoe prior and studies its convergence rates in several high-dimensional models.
15. Topics in Measurement Error Analysis and High-Dimensional Binary Classification
This dissertation proposes novel methods to tackle two problems: the misspecified model with measurement error and high-dimensional binary classification, both have a crucial impact on applications in public health. The first problem exists in the epidemiology practice. Epidemiologists often categorize a continuous risk predictor since categorization is thought to be more robust and interpretable, even when the true risk model is not a categorical one. Thus, their goal is to fit the categorical model and interpret the categorical parameters. The second project considers the problem of high-dimensional classification between the two groups with unequal covariance matrices. Rather than estimating the full quadratic discriminant rule, it is proposed to perform simultaneous variable selection and linear dimension reduction on original data, with the subsequent application of quadratic discriminant analysis on the reduced space. Further, in order to support the proposed methodology, two R packages were developed, CCP and DAP, along with two vignettes as long-format illustrations for their usage.
16. Model-Based Penalized Regression
This dissertation contains three chapters that consider penalized regression from a model-based perspective, interpreting penalties as assumed prior distributions for unknown regression coefficients. The first chapter shows that treating a lasso penalty as a prior can facilitate the choice of tuning parameters when standard methods for choosing the tuning parameters are not available, and when it is necessary to choose multiple tuning parameters simultaneously. The second chapter considers a possible drawback of treating penalties as models, specifically possible misspecification. The third chapter introduces structured shrinkage priors for dependent regression coefficients which generalize popular independent shrinkage priors. These can be useful in various applied settings where many regression coefficients are not only expected to be nearly or exactly equal to zero, but also structured.
17. Topics on Least Squares Estimation
This dissertation revisits and makes progress on some old but challenging problems concerning least squares estimation, the work-horse of supervised machine learning. Two major problems are addressed: (i) least squares estimation with heavy-tailed errors, and (ii) least squares estimation in non-Donsker classes. For (i), this problem is studied both from a worst-case perspective, and a more refined envelope perspective. For (ii), two case studies are performed in the context of (a) estimation involving sets and (b) estimation of multivariate isotonic functions. Understanding these particular aspects of least squares estimation problems requires several new tools in the empirical process theory, including a sharp multiplier inequality controlling the size of the multiplier empirical process, and matching upper and lower bounds for empirical processes indexed by non-Donsker classes.
How to Learn More about Machine Learning
At our upcoming event this November 16th-18th in San Francisco, ODSC West 2021 will feature a plethora of talks, workshops, and training sessions on machine learning and machine learning research. You can register now for 50% off all ticket types before the discount drops to 40% in a few weeks. Some highlighted sessions on machine learning include:
- Towards More Energy-Efficient Neural Networks? Use Your Brain!: Olaf de Leeuw | Data Scientist | Dataworkz
- Practical MLOps: Automation Journey: Evgenii Vinogradov, PhD | Head of DHW Development | YooMoney
- Applications of Modern Survival Modeling with Python: Brian Kent, PhD | Data Scientist | Founder The Crosstab Kite
- Using Change Detection Algorithms for Detecting Anomalous Behavior in Large Systems: Veena Mendiratta, PhD | Adjunct Faculty, Network Reliability and Analytics Researcher | Northwestern University
Sessions on MLOps:
- Tuning Hyperparameters with Reproducible Experiments: Milecia McGregor | Senior Software Engineer | Iterative
- MLOps… From Model to Production: Filipa Peleja, PhD | Lead Data Scientist | Levi Strauss & Co
- Operationalization of Models Developed and Deployed in Heterogeneous Platforms: Sourav Mazumder | Data Scientist, Thought Leader, AI & ML Operationalization Leader | IBM
- Develop and Deploy a Machine Learning Pipeline in 45 Minutes with Ploomber: Eduardo Blancas | Data Scientist | Fidelity Investments
Sessions on Deep Learning:
- GANs: Theory and Practice, Image Synthesis With GANs Using TensorFlow: Ajay Baranwal | Center Director | Center for Deep Learning in Electronic Manufacturing, Inc
- Machine Learning With Graphs: Going Beyond Tabular Data: Dr. Clair J. Sullivan | Data Science Advocate | Neo4j
- Deep Dive into Reinforcement Learning with PPO using TF-Agents & TensorFlow 2.0: Oliver Zeigermann | Software Developer | embarc Software Consulting GmbH
- Get Started with Time-Series Forecasting using the Google Cloud AI Platform: Karl Weinmeister | Developer Relations Engineering Manager | Google

Daniel Gutierrez, ODSC
Daniel D. Gutierrez is a practicing data scientist who’s been working with data long before the field came in vogue. As a technology journalist, he enjoys keeping a pulse on this fast-paced industry. Daniel is also an educator having taught data science, machine learning and R classes at the university level. He has authored four computer industry books on database and data science technology, including his most recent title, “Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R.” Daniel holds a BS in Mathematics and Computer Science from UCLA.

HHS Outlines New Framework for Responsible AI Use in Public Benefits Administration
AI and Data Science News posted by ODSC Team May 4, 2024 In a move toward modernizing public benefits administration, the U.S. Department of Health and Human Services...

OpenAI Looks to Balance Risks and Model Capabilities
AI and Data Science News posted by ODSC Team May 3, 2024 OpenAI is working to remain at the forefront of artificial intelligence, but with that desire comes...

Podcast: Data Science Interview Tips & Tricks with Microsoft’s Leondra Gonzalez
Podcast Career Insights posted by ODSC Team May 3, 2024 Learn about cutting-edge developments in AI and Data Science from the experts who know them best...

Top 15+ Big Data Dissertation Topics
The term big data refers to the technology which processes a huge amount of data in various formats within a fraction of seconds . Big data handles the research domains by means of managing their data loads. Big data dissertation helps to convey the perceptions on the proposed research problems. It is also known as the new generation technology which could compatible with high-speed data acquisitions, storage, and analytics . From this article, you will come to know the big data dissertation topics with their relevant justifications”
In general, dissertation writing is one of the irreplaceable parts of the research . A well-drafted dissertation helps you to point out the issues and solutions of the researched area to the other opponents . Our technical team has framed this article with the introduction of big data fundamentals to make you understand. At the end of this article, you are going to become a master in the areas of dissertation topics without any doubts. Shall we move on to the upcoming areas? Let’s move to get into the article.

Fundamentals of Big Data
- Pattern Analytics
- Sentiment Analysis
- Block Modeling
- Association Rule Mining
- Partitioning Nodes
- Cassandra & Oozie
- Hbase & JAQL
- Mahout & Hadoop
- Hive & Middleware
- Pig & MapReduce
- Demographical Data
- Social Media Data
- Multimedia Data
- Crime Incidents
- Financial Reports
- Telephone Histories
- Network Location Data
- Observation Logs
The above listed are the aspects that are getting comprised in the fundamentals of big data . Big data is the technology to progress a huge amount of data with homogeneity by numerous concepts. Big data applications can be deployed in any of the fields to achieve extreme results in the determined areas of research/projects . In the subsequent areas, we mentioned to you the pipeline architecture of the big data for the ease of your understanding.
Big data progresses the unstructured data and normalizes the same in the human-readable formats. Our technical crew is very much sure about every concept of big data technology . Now let us move on to the next phase. Are you interested in stepping into the next section? Come we will learn together.
Pipeline Architecture for Big Data
- Data Warranty
- Data Cleaning
- Meta Data Managing
- Raw & Normalized Logs Storage
- Prescriptive & Descriptive
- Pattern Recognition
- Machine Learning & AI
- Statistical Data Mining
- Decision Support Methods
- Visualized Dashboards
- Alerting & Reporting Systems
This is how the big data architecture is built in real-time. Generally, manual working with a massive amount of data leads to too much time ingestions. Besides, you need to get familiar with the big data technical concepts to exclude these limitations . Usually, it needs experts’ pieces of advice to learn the eminent and crucial edges of those overlays.
In addition, here we wanted to remark about our incredible abilities in handling big data technologies. You might get wondered about us! We are a company with numerous skilled top engineers who are dynamically particularly performing the big data dissertation topics. Are you ready to know about us? Let’s move on to the next phase!
Our Experts Skillsets in Big Data
- Familiar with Hadoop & Cloud era etc.
- Google & AWS cloud deployment practices
- Virtuous inherent writing skillsets
- Experts in handling the bottlenecks with various tools
- Masters in big data concepts
- Experts in IoT, deep learning, machine learning & data mining
- Conversant with software, hardware, myriad & Matlab tools
- Experts in multivariable calculus, matrix & linear algebra
- Highly aware of Hadoop , SQL, R, Hive & Scala
- Proficient in Python, Java, C++ & R
The aforementioned are the various skillsets of our technical team. We are delivering the big data and other projects/researches by interpreting with these techniques and abilities. So far, we have discussed the basic concepts of big data analytics . We thought that it would be the right time to reveal the major features that overlap in big data analytics for the ease of your understanding. Shall we guys get into that phase? Here we go!!!
Major Features of Big Data Analytics
- Optimization of data storage
- Processing large volume of data
- Relevant search option
- Feedbacks update and work precisely
The listed above passage conveyed to you the features that manipulate the workflow of big data . As the matter of fact, our technical team with experts is frequently updating them according to the trends in the technology industry and solves the problems that arise in it. As this article is concentrated on the big data dissertation topics, our experts want to highlight the major problems that get up in big data management to improve your skill sets in that areas too. Let us have the next section!!!
Major Problems in Big Data
- Difficult to work with the different data formats
- Massive unstructured data ranges from videos, data & image
- Region-wise privacy control variations make much complex
- Trains the decentralized data models
- Accommodates with the regulatory in which data cannot be shared
- Requires improved local models in each boundary
- Hardware or software level security is big a challenge
- It fails to preserve the sensitive fields in the healthcare systems
- For instance, it reveals the personal health records visibly
- It fails to recognize the abnormalities (anomalies) of the big data
- In addition, it is the major issue in telecom domains
- Effective graph processing is needed in social media analysis
- It fails to handle the large scale graph processing
- Spark & Hadoop processes the online & offline data formats
- It requires improved scalability to process the parallel big data
- Videos are the public data transmission medium
- For instance CCTV footages, YouTube, and other social media video clips
- Data storage in cloud systems are a challenging issue here
- Inaccurate / Partial & Low Reliability is the biggest issue here
- Unlabeled data vagueness makes it much complex
- It results in data omission & ineffective data propagation
- Leads to understand the meaning in different ways
- Visualization of the massive amount of data dimensions are not possible
- Results in spreading rumors unconditionally
- Fake data sources are Whatsapp, Twitters & forged URLs
The listed above are the major problems that are being faced in big data technologies. However, these issues can be eradicated by the deployment of several tools along with improving the techniques of the same. In fact, this phase needs experts guidance. We do have world-class certified engineers to perform in emerging technologies.
If you are facing any issues in these areas while experimenting you can approach our researchers at any time. We are always welcoming the students to get benefits from us.
In a matter of fact, our technical crew is very much intelligent in handling the thesis/dissertation as well as familiar in the areas of big data projects and researches. Yes, we are going to cover the next section by highlighting the recent big data dissertation topics for your better understanding. As we reserved the unique places in the industries, we are being trusted blindly in the event of providing the unimaginable innovations in the determined dissertation and other works.
Recent Big Data Dissertation Topics
- Huge Scale Key-Value Storing & Data Distribution by Kinetic Drives
- Blocking Falls / HOL Deadlock Freedom & Minimal Path Routing by Smart-queuing
- Digital 5D Network Applications by Lessor Dimensionality Elements
- Effective Biological Network Analytics by Graph Theory Sampling Methods
- Advanced Big Data Segmentation (unfair) by Boosted Sampling Methods
- Collaborative Filtering & Huge Scale Bipartite Rating Graphs by Spark
- DDoS Attack Mitigation by IoT & SDN
- Termination of Tasks by Drive Diagnostic Data Center Attribution System
- Container Resource Integrations by Hadoop Transcoding Cluster Split Samples
- Retail Supply Chain Decision Making & Alerting System by Cloud Computing
- Sensitive Processes by Collaborative Filtering Algorithm & Quality Variance Methods
- Keyword Searches in Proxy Servers & Cloud Computing by Cryptography
- Non-Collaborative (Game) Cloud Computing by Task Scheduling Algorithm
- Multi-core Parallelizing & Overlapping by Speaker Listener Label Propagation
- Bipartite Graphs for Vacation Spots by Inventive Recommendation Frameworks
The above listed are some of the big data dissertation topics . In this section we have used some acronyms; we thought that you might need their explanations to understand the same.
- SDN- Software Defined Networking
- DDoS- Distributed Denial of Service
- IoT- Internet of Things
Let’s begin your dissertation works by envisaging these as your references. We hope that you are getting the points as of now listed. As the matter of fact, we are offering the dissertation services at the lowest cost compared to others. In addition to that, we have delivered more than 10,000 big data dissertations till now.
To be honest, each big data dissertation has a unique quality and we never imitate the contents as represented in the other dissertations. This makes us irreplaceable from others. If you are interested, let’s join your hands with us to experience the inexperienced technical fields. In addition to these sections, we have also wanted to encompass the big data analytics tools for the ease of your understanding. Let’s have that section!

Big Data Analytics Tools
- Imports data from RDBMS and sends to the Hadoop systems for queries
- Runs the aggregated queries & generates the columnar based database
- Sums up the incidences and words in the given inputs
- Stores the massive unstructured data & acts as a data streaming mode
- Computational open source big data tool with real-time occurrences
- Analyses & processes the immense amount of data robustly
- Handles the data portions effectively (chunks) & distributed DB
- Manages and integrates the big data acquisitions
- Deals with the dynamic datasets
- Analyses & warehouses the huge amount of data
The aforementioned are the top big data analytical tools . In those tools, Spark & Kafka writes simple window sliding queries to identify the necessary data. Open source datasets & log data parsing can be practiced if you become familiar with the functionalities and concepts of the big data analytical tools. So far, we have learned in the areas of big data dissertation topics. We hope that you would have enjoyed this article as this is conveyed to you the very essential aspects with crystal clear points. We are hoping for your explorations.
“Let’s start to light up your envisaged ideologies and thoughts in the forms of technology”
Why Work With Us ?
Senior research member, research experience, journal member, book publisher, research ethics, business ethics, valid references, explanations, paper publication, 9 big reasons to select us.
Our Editor-in-Chief has Website Ownership who control and deliver all aspects of PhD Direction to scholars and students and also keep the look to fully manage all our clients.
Our world-class certified experts have 18+years of experience in Research & Development programs (Industrial Research) who absolutely immersed as many scholars as possible in developing strong PhD research projects.
We associated with 200+reputed SCI and SCOPUS indexed journals (SJR ranking) for getting research work to be published in standard journals (Your first-choice journal).
PhDdirection.com is world’s largest book publishing platform that predominantly work subject-wise categories for scholars/students to assist their books writing and takes out into the University Library.
Our researchers provide required research ethics such as Confidentiality & Privacy, Novelty (valuable research), Plagiarism-Free, and Timely Delivery. Our customers have freedom to examine their current specific research activities.
Our organization take into consideration of customer satisfaction, online, offline support and professional works deliver since these are the actual inspiring business factors.
Solid works delivering by young qualified global research team. "References" is the key to evaluating works easier because we carefully assess scholars findings.
Detailed Videos, Readme files, Screenshots are provided for all research projects. We provide Teamviewer support and other online channels for project explanation.
Worthy journal publication is our main thing like IEEE, ACM, Springer, IET, Elsevier, etc. We substantially reduces scholars burden in publication side. We carry scholars from initial submission to final acceptance.
Related Pages
Our benefits, throughout reference, confidential agreement, research no way resale, plagiarism-free, publication guarantee, customize support, fair revisions, business professionalism, domains & tools, we generally use, wireless communication (4g lte, and 5g), ad hoc networks (vanet, manet, etc.), wireless sensor networks, software defined networks, network security, internet of things (mqtt, coap), internet of vehicles, cloud computing, fog computing, edge computing, mobile computing, mobile cloud computing, ubiquitous computing, digital image processing, medical image processing, pattern analysis and machine intelligence, geoscience and remote sensing, big data analytics, data mining, power electronics, web of things, digital forensics, natural language processing, automation systems, artificial intelligence, mininet 2.1.0, matlab (r2018b/r2019a), matlab and simulink, apache hadoop, apache spark mlib, apache mahout, apache flink, apache storm, apache cassandra, pig and hive, rapid miner, support 24/7, call us @ any time, +91 9444829042, [email protected].
Questions ?
Click here to chat with us
- Bibliography
- More Referencing guides Blog Automated transliteration Relevant bibliographies by topics
- Automated transliteration
- Relevant bibliographies by topics
- Referencing guides
Dissertations / Theses on the topic 'Big data frameworks'
Create a spot-on reference in apa, mla, chicago, harvard, and other styles.
Consult the top 50 dissertations / theses for your research on the topic 'Big data frameworks.'
Next to every source in the list of references, there is an 'Add to bibliography' button. Press on it, and we will generate automatically the bibliographic reference to the chosen work in the citation style you need: APA, MLA, Harvard, Chicago, Vancouver, etc.
You can also download the full text of the academic publication as pdf and read online its abstract whenever available in the metadata.
Browse dissertations / theses on a wide variety of disciplines and organise your bibliography correctly.
Nyström, Simon, and Joakim Lönnegren. "Processing data sources with big data frameworks." Thesis, KTH, Data- och elektroteknik, 2016. http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-188204.
Bao, Shunxing. "Algorithmic Enhancements to Data Colocation Grid Frameworks for Big Data Medical Image Processing." Thesis, Vanderbilt University, 2019. http://pqdtopen.proquest.com/#viewpdf?dispub=13877282.
Large-scale medical imaging studies to date have predominantly leveraged in-house, laboratory-based or traditional grid computing resources for their computing needs, where the applications often use hierarchical data structures (e.g., Network file system file stores) or databases (e.g., COINS, XNAT) for storage and retrieval. The resulting performance for laboratory-based approaches reveal that performance is impeded by standard network switches since typical processing can saturate network bandwidth during transfer from storage to processing nodes for even moderate-sized studies. On the other hand, the grid may be costly to use due to the dedicated resources used to execute the tasks and lack of elasticity. With increasing availability of cloud-based big data frameworks, such as Apache Hadoop, cloud-based services for executing medical imaging studies have shown promise.
Despite this promise, our studies have revealed that existing big data frameworks illustrate different performance limitations for medical imaging applications, which calls for new algorithms that optimize their performance and suitability for medical imaging. For instance, Apache HBases data distribution strategy of region split and merge is detrimental to the hierarchical organization of imaging data (e.g., project, subject, session, scan, slice). Big data medical image processing applications involving multi-stage analysis often exhibit significant variability in processing times ranging from a few seconds to several days. Due to the sequential nature of executing the analysis stages by traditional software technologies and platforms, any errors in the pipeline are only detected at the later stages despite the sources of errors predominantly being the highly compute-intensive first stage. This wastes precious computing resources and incurs prohibitively higher costs for re-executing the application. To address these challenges, this research propose a framework - Hadoop & HBase for Medical Image Processing (HadoopBase-MIP) - which develops a range of performance optimization algorithms and employs a number of system behaviors modeling for data storage, data access and data processing. We also introduce how to build up prototypes to help empirical system behaviors verification. Furthermore, we introduce a discovery with the development of HadoopBase-MIP about a new type of contrast for medical imaging deep brain structure enhancement. And finally we show how to move forward the Hadoop based framework design into a commercialized big data / High performance computing cluster with cheap, scalable and geographically distributed file system.
Carvalho, Rafael Aquino de. "Uma análise comparativa de ambientes para Big Data: Apche Spark e HPAT." Universidade de São Paulo, 2018. http://www.teses.usp.br/teses/disponiveis/45/45134/tde-15062018-110116/.
Lemon, Alexander Michael. "A Shared-Memory Coupled Architecture to Leverage Big Data Frameworks in Prototyping and In-Situ Analytics for Data Intensive Scientific Workflows." BYU ScholarsArchive, 2019. https://scholarsarchive.byu.edu/etd/7545.
Kurt, Mehmet Can. "Fault-tolerant Programming Models and Computing Frameworks." The Ohio State University, 2015. http://rave.ohiolink.edu/etdc/view?acc_num=osu1437390499.
Lakoju, Mike. "A strategic approach of value identification for a big data project." Thesis, Brunel University, 2017. http://bura.brunel.ac.uk/handle/2438/15837.
Ainslie, Mandi. "Big data and privacy : a modernised framework." Diss., University of Pretoria, 2017. http://hdl.handle.net/2263/59805.
Su, Yu. "Big Data Management Framework based on Virtualization and Bitmap Data Summarization." The Ohio State University, 2015. http://rave.ohiolink.edu/etdc/view?acc_num=osu1420738636.
Bock, Matthew. "A Framework for Hadoop Based Digital Libraries of Tweets." Thesis, Virginia Tech, 2017. http://hdl.handle.net/10919/78351.
Teske, Alexander. "Automated Risk Management Framework with Application to Big Maritime Data." Thesis, Université d'Ottawa / University of Ottawa, 2018. http://hdl.handle.net/10393/38567.
Jayapandian, Catherine Praveena. "Cloudwave: A Cloud Computing Framework for Multimodal Electrophysiological Big Data." Case Western Reserve University School of Graduate Studies / OhioLINK, 2014. http://rave.ohiolink.edu/etdc/view?acc_num=case1405516626.
Sweeney, Michael John. "A framework for scoring and tagging NetFlow data." Thesis, Rhodes University, 2019. http://hdl.handle.net/10962/65022.
Orenga, Roglá Sergio. "Framework for the Implementation of a Big Data Ecosystem in Organizations." Doctoral thesis, Universitat Jaume I, 2017. http://hdl.handle.net/10803/481983.
Mgudlwa, Sibulela. "A big data analytics framework to improve healthcare service delivery in South Africa." Thesis, Cape Peninsula University of Technology, 2018. http://hdl.handle.net/20.500.11838/2877.
Forresi, Chiara. "Un framework per l'analisi di big data con elevata eterogeneità all'interno di multistore." Master's thesis, Alma Mater Studiorum - Università di Bologna, 2020. http://amslaurea.unibo.it/21411/.
Li, Zhen. "CloudVista: a Framework for Interactive Visual Cluster Exploration of Big Data in the Cloud." Wright State University / OhioLINK, 2012. http://rave.ohiolink.edu/etdc/view?acc_num=wright1348204863.
Carneiro, Tiago Reis. "Impacto do big data e analytics na performance da industria hoteleira nacional." Master's thesis, Instituto Superior de Economia e Gestão, 2017. http://hdl.handle.net/10400.5/15103.
Buono, Nicola. "Un framework per la predizione del contesto utente." Bachelor's thesis, Alma Mater Studiorum - Università di Bologna, 2019. http://amslaurea.unibo.it/17716/.
Huang, Xin. "Querying big RDF data : semantic heterogeneity and rule-based inconsistency." Thesis, Sorbonne Paris Cité, 2016. http://www.theses.fr/2016USPCB124/document.
Berglund, Jesper. "An automated approach to clustering with the framework suggested by Bradley, Fayyad and Reina." Thesis, KTH, Skolan för elektroteknik och datavetenskap (EECS), 2018. http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-238736.
Cofré, Martel Sergio Manuel Ignacio. "A deep learning based framework for physical assets' health prognostics under uncertainty for big Machinery Data." Tesis, Universidad de Chile, 2018. http://repositorio.uchile.cl/handle/2250/168080.
Chen, Jiahong. "Data protection in the age of Big Data : legal challenges and responses in the context of online behavioural advertising." Thesis, University of Edinburgh, 2018. http://hdl.handle.net/1842/33149.
Zhang, Jianzhe. "Development of an Apache Spark-Based Framework for Processing and Analyzing Neuroscience Big Data: Application in Epilepsy Using EEG Signal Data." Case Western Reserve University School of Graduate Studies / OhioLINK, 2020. http://rave.ohiolink.edu/etdc/view?acc_num=case1597089028333942.
Calabria, Francesco. "Il Framework RAM3S: Generalizzazione ed Estensione." Master's thesis, Alma Mater Studiorum - Università di Bologna, 2018.
Aved, Alexander. "Scene Understanding for Real Time Processing of Queries over Big Data Streaming Video." Doctoral diss., University of Central Florida, 2013. http://digital.library.ucf.edu/cdm/ref/collection/ETD/id/5597.
Bursztyn, Damián. "Répondre efficacement aux requêtes Big Data en présence de contraintes." Thesis, Université Paris-Saclay (ComUE), 2016. http://www.theses.fr/2016SACLS567/document.
Nguyen, Ngoc Buu Cat. "Data Mining in Knowledge Management Processes: Developing an Implementing Framework." Thesis, Umeå universitet, Institutionen för informatik, 2018. http://urn.kb.se/resolve?urn=urn:nbn:se:umu:diva-149668.
KNOBEL, KARIN, and LOVISA LÆSTADIUS. "Big Data in Performance Measurement: : Towards a Framework for Performance Measurement in a Digital and Dynamic Business Climate." Thesis, KTH, Skolan för industriell teknik och management (ITM), 2018. http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-238689.
Yang, Bin, and 杨彬. "A novel framework for binning environmental genomic fragments." Thesis, The University of Hong Kong (Pokfulam, Hong Kong), 2010. http://hub.hku.hk/bib/B45789344.
張美玲 and Mei-ling Lisa Cheung. "An evaluation framework for internet lexicography." Thesis, The University of Hong Kong (Pokfulam, Hong Kong), 2000. http://hub.hku.hk/bib/B31944553.
Leung, Yuk-yee, and 梁玉儀. "An integrated framework for feature selection and classification in microarray data analysis." Thesis, The University of Hong Kong (Pokfulam, Hong Kong), 2009. http://hub.hku.hk/bib/B43278632.
Alshaer, Mohammad. "An Efficient Framework for Processing and Analyzing Unstructured Text to Discover Delivery Delay and Optimization of Route Planning in Realtime." Thesis, Lyon, 2019. http://www.theses.fr/2019LYSE1105/document.
Coimbra, Rafael Melo. "Framework based on lambda architecture applied to IoT: case scenario." Master's thesis, Universidade de Aveiro, 2016. http://hdl.handle.net/10773/21739.
Semenski, Vedran. "An ABAC framework for IoT applications based on the OASIS XACML standard." Master's thesis, Universidade de Aveiro, 2015. http://hdl.handle.net/10773/18493.
Chen, Yuanfang. "Mobile collaborative sensing : framework and algorithm design." Thesis, Evry, Institut national des télécommunications, 2017. http://www.theses.fr/2017TELE0016/document.
Riegel, Ryan Nelson. "Generalized N-body problems: a framework for scalable computation." Diss., Georgia Institute of Technology, 2013. http://hdl.handle.net/1853/50269.
Lee, Yong Cheol. "Rule logic and its validation framework of model view definitions for building information modeling." Diss., Georgia Institute of Technology, 2015. http://hdl.handle.net/1853/54430.
Karlstedt, Johan M. "An ISD study of Extreme Information Management challenges in IoT Systems - Case : The “OpenSenses”eHealth/Smarthome project." Thesis, Blekinge Tekniska Högskola, Sektionen för datavetenskap och kommunikation, 2012. http://urn.kb.se/resolve?urn=urn:nbn:se:bth-4821.
von, Wenckstern Michael. "Web applications using the Google Web Toolkit." Master's thesis, Technische Universitaet Bergakademie Freiberg Universitaetsbibliothek "Georgius Agricola", 2013. http://nbn-resolving.de/urn:nbn:de:bsz:105-qucosa-115009.
Chen, Chao Hsu, and 陳潮旭. "A Study on Open Source Frameworks for Big Data Analytics." Thesis, 2016. http://ndltd.ncl.edu.tw/handle/9tu5j7.
Miranda, Cristiano José Ribeiro. "Processamento em streaming: avaliação de frameworks em contexto Big Data." Master's thesis, 2018. http://hdl.handle.net/1822/59130.
(10692924), Bara M. Abusalah. "DEPENDABLE CLOUD RESOURCES FOR BIG-DATA BATCH PROCESSING & STREAMING FRAMEWORKS." Thesis, 2021.
Yao, Yi-Cheng, and 姚奕丞. "An Automatic Pre-Processing Framework for Big Data." Thesis, 2016. http://ndltd.ncl.edu.tw/handle/58812215485504227958.
Chrimes, Dillon. "Towards a big data analytics platform with Hadoop/MapReduce framework using simulated patient data of a hospital system." Thesis, 2016. http://hdl.handle.net/1828/7645.
Hsieh, Tsung Ju, and 謝宗儒. "Continuous Audit Mechanism Using a Big Data Analytics Framework." Thesis, 2014. http://ndltd.ncl.edu.tw/handle/2759s3.
Shih, Jhih-Cheng, and 施志承. "A Framework to Support Hyper Big Data Integration and Management." Thesis, 2015. http://ndltd.ncl.edu.tw/handle/67359013162352975835.
Chang, Yu-Jui, and 張有睿. "An adaptively multi-attribute index framework for big IoT data." Thesis, 2019. http://ndltd.ncl.edu.tw/handle/5xcdb6.
Amankwah-Amoah, J., and Samuel Adomako. "Big Data Analytics and Business Failures in Data-Rich Environments: An Organizing Framework." 2018. http://hdl.handle.net/10454/16746.
Shieh, Jeng-Peng, and 謝正鵬. "An Adaptive Code/Object Offloading Framework for Personalized Big-Data Computing." Thesis, 2015. http://ndltd.ncl.edu.tw/handle/60606246242372908678.
Byrne, Thomas J., I. Felician Campean, and Daniel Neagu. "Towards a framework for engineering big data: An automotive systems perspective." 2018. http://hdl.handle.net/10454/15655.
- How It Works
- PhD thesis writing
- Master thesis writing
- Bachelor thesis writing
- Dissertation writing service
- Dissertation abstract writing
- Thesis proposal writing
- Thesis editing service
- Thesis proofreading service
- Thesis formatting service
- Coursework writing service
- Research paper writing service
- Architecture thesis writing
- Computer science thesis writing
- Engineering thesis writing
- History thesis writing
- MBA thesis writing
- Nursing dissertation writing
- Psychology dissertation writing
- Sociology thesis writing
- Statistics dissertation writing
- Buy dissertation online
- Write my dissertation
- Cheap thesis
- Cheap dissertation
- Custom dissertation
- Dissertation help
- Pay for thesis
- Pay for dissertation
- Senior thesis
- Write my thesis
214 Best Big Data Research Topics for Your Thesis Paper

Finding an ideal big data research topic can take you a long time. Big data, IoT, and robotics have evolved. The future generations will be immersed in major technologies that will make work easier. Work that was done by 10 people will now be done by one person or a machine. This is amazing because, in as much as there will be job loss, more jobs will be created. It is a win-win for everyone.
Big data is a major topic that is being embraced globally. Data science and analytics are helping institutions, governments, and the private sector. We will share with you the best big data research topics.
On top of that, we can offer you the best writing tips to ensure you prosper well in your academics. As students in the university, you need to do proper research to get top grades. Hence, you can consult us if in need of research paper writing services.
Big Data Analytics Research Topics for your Research Project
Are you looking for an ideal big data analytics research topic? Once you choose a topic, consult your professor to evaluate whether it is a great topic. This will help you to get good grades.
- Which are the best tools and software for big data processing?
- Evaluate the security issues that face big data.
- An analysis of large-scale data for social networks globally.
- The influence of big data storage systems.
- The best platforms for big data computing.
- The relation between business intelligence and big data analytics.
- The importance of semantics and visualization of big data.
- Analysis of big data technologies for businesses.
- The common methods used for machine learning in big data.
- The difference between self-turning and symmetrical spectral clustering.
- The importance of information-based clustering.
- Evaluate the hierarchical clustering and density-based clustering application.
- How is data mining used to analyze transaction data?
- The major importance of dependency modeling.
- The influence of probabilistic classification in data mining.
Interesting Big Data Analytics Topics
Who said big data had to be boring? Here are some interesting big data analytics topics that you can try. They are based on how some phenomena are done to make the world a better place.
- Discuss the privacy issues in big data.
- Evaluate the storage systems of scalable in big data.
- The best big data processing software and tools.
- Data mining tools and techniques are popularly used.
- Evaluate the scalable architectures for parallel data processing.
- The major natural language processing methods.
- Which are the best big data tools and deployment platforms?
- The best algorithms for data visualization.
- Analyze the anomaly detection in cloud servers
- The scrutiny normally done for the recruitment of big data job profiles.
- The malicious user detection in big data collection.
- Learning long-term dependencies via the Fourier recurrent units.
- Nomadic computing for big data analytics.
- The elementary estimators for graphical models.
- The memory-efficient kernel approximation.
Big Data Latest Research Topics
Do you know the latest research topics at the moment? These 15 topics will help you to dive into interesting research. You may even build on research done by other scholars.
- Evaluate the data mining process.
- The influence of the various dimension reduction methods and techniques.
- The best data classification methods.
- The simple linear regression modeling methods.
- Evaluate the logistic regression modeling.
- What are the commonly used theorems?
- The influence of cluster analysis methods in big data.
- The importance of smoothing methods analysis in big data.
- How is fraud detection done through AI?
- Analyze the use of GIS and spatial data.
- How important is artificial intelligence in the modern world?
- What is agile data science?
- Analyze the behavioral analytics process.
- Semantic analytics distribution.
- How is domain knowledge important in data analysis?
Big Data Debate Topics
If you want to prosper in the field of big data, you need to try even hard topics. These big data debate topics are interesting and will help you to get a better understanding.
- The difference between big data analytics and traditional data analytics methods.
- Why do you think the organization should think beyond the Hadoop hype?
- Does the size of the data matter more than how recent the data is?
- Is it true that bigger data are not always better?
- The debate of privacy and personalization in maintaining ethics in big data.
- The relation between data science and privacy.
- Do you think data science is a rebranding of statistics?
- Who delivers better results between data scientists and domain experts?
- According to your view, is data science dead?
- Do you think analytics teams need to be centralized or decentralized?
- The best methods to resource an analytics team.
- The best business case for investing in analytics.
- The societal implications of the use of predictive analytics within Education.
- Is there a need for greater control to prevent experimentation on social media users without their consent?
- How is the government using big data; for the improvement of public statistics or to control the population?
University Dissertation Topics on Big Data
Are you doing your Masters or Ph.D. and wondering the best dissertation topic or thesis to do? Why not try any of these? They are interesting and based on various phenomena. While doing the research ensure you relate the phenomenon with the current modern society.
- The machine learning algorithms are used for fall recognition.
- The divergence and convergence of the internet of things.
- The reliable data movements using bandwidth provision strategies.
- How is big data analytics using artificial neural networks in cloud gaming?
- How is Twitter accounts classification done using network-based features?
- How is online anomaly detection done in the cloud collaborative environment?
- Evaluate the public transportation insights provided by big data.
- Evaluate the paradigm for cancer patients using the nursing EHR to predict the outcome.
- Discuss the current data lossless compression in the smart grid.
- How does online advertising traffic prediction helps in boosting businesses?
- How is the hyperspectral classification done using the multiple kernel learning paradigm?
- The analysis of large data sets downloaded from websites.
- How does social media data help advertising companies globally?
- Which are the systems recognizing and enforcing ownership of data records?
- The alternate possibilities emerging for edge computing.
The Best Big Data Analysis Research Topics and Essays
There are a lot of issues that are associated with big data. Here are some of the research topics that you can use in your essays. These topics are ideal whether in high school or college.
- The various errors and uncertainty in making data decisions.
- The application of big data on tourism.
- The automation innovation with big data or related technology
- The business models of big data ecosystems.
- Privacy awareness in the era of big data and machine learning.
- The data privacy for big automotive data.
- How is traffic managed in defined data center networks?
- Big data analytics for fault detection.
- The need for machine learning with big data.
- The innovative big data processing used in health care institutions.
- The money normalization and extraction from texts.
- How is text categorization done in AI?
- The opportunistic development of data-driven interactive applications.
- The use of data science and big data towards personalized medicine.
- The programming and optimization of big data applications.
The Latest Big Data Research Topics for your Research Proposal
Doing a research proposal can be hard at first unless you choose an ideal topic. If you are just diving into the big data field, you can use any of these topics to get a deeper understanding.
- The data-centric network of things.
- Big data management using artificial intelligence supply chain.
- The big data analytics for maintenance.
- The high confidence network predictions for big biological data.
- The performance optimization techniques and tools for data-intensive computation platforms.
- The predictive modeling in the legal context.
- Analysis of large data sets in life sciences.
- How to understand the mobility and transport modal disparities sing emerging data sources?
- How do you think data analytics can support asset management decisions?
- An analysis of travel patterns for cellular network data.
- The data-driven strategic planning for citywide building retrofitting.
- How is money normalization done in data analytics?
- Major techniques used in data mining.
- The big data adaptation and analytics of cloud computing.
- The predictive data maintenance for fault diagnosis.
Interesting Research Topics on A/B Testing In Big Data
A/B testing topics are different from the normal big data topics. However, you use an almost similar methodology to find the reasons behind the issues. These topics are interesting and will help you to get a deeper understanding.
- How is ultra-targeted marketing done?
- The transition of A/B testing from digital to offline.
- How can big data and A/B testing be done to win an election?
- Evaluate the use of A/B testing on big data
- Evaluate A/B testing as a randomized control experiment.
- How does A/B testing work?
- The mistakes to avoid while conducting the A/B testing.
- The most ideal time to use A/B testing.
- The best way to interpret results for an A/B test.
- The major principles of A/B tests.
- Evaluate the cluster randomization in big data
- The best way to analyze A/B test results and the statistical significance.
- How is A/B testing used in boosting businesses?
- The importance of data analysis in conversion research
- The importance of A/B testing in data science.
Amazing Research Topics on Big Data and Local Governments
Governments are now using big data to make the lives of the citizens better. This is in the government and the various institutions. They are based on real-life experiences and making the world better.
- Assess the benefits and barriers of big data in the public sector.
- The best approach to smart city data ecosystems.
- The big analytics used for policymaking.
- Evaluate the smart technology and emergence algorithm bureaucracy.
- Evaluate the use of citizen scoring in public services.
- An analysis of the government administrative data globally.
- The public values are found in the era of big data.
- Public engagement on local government data use.
- Data analytics use in policymaking.
- How are algorithms used in public sector decision-making?
- The democratic governance in the big data era.
- The best business model innovation to be used in sustainable organizations.
- How does the government use the collected data from various sources?
- The role of big data for smart cities.
- How does big data play a role in policymaking?
Easy Research Topics on Big Data
Who said big data topics had to be hard? Here are some of the easiest research topics. They are based on data management, research, and data retention. Pick one and try it!
- Who uses big data analytics?
- Evaluate structure machine learning.
- Explain the whole deep learning process.
- Which are the best ways to manage platforms for enterprise analytics?
- Which are the new technologies used in data management?
- What is the importance of data retention?
- The best way to work with images is when doing research.
- The best way to promote research outreach is through data management.
- The best way to source and manage external data.
- Does machine learning improve the quality of data?
- Describe the security technologies that can be used in data protection.
- Evaluate token-based authentication and its importance.
- How can poor data security lead to the loss of information?
- How to determine secure data.
- What is the importance of centralized key management?
Unique IoT and Big Data Research Topics
Internet of Things has evolved and many devices are now using it. There are smart devices, smart cities, smart locks, and much more. Things can now be controlled by the touch of a button.
- Evaluate the 5G networks and IoT.
- Analyze the use of Artificial intelligence in the modern world.
- How do ultra-power IoT technologies work?
- Evaluate the adaptive systems and models at runtime.
- How have smart cities and smart environments improved the living space?
- The importance of the IoT-based supply chains.
- How does smart agriculture influence water management?
- The internet applications naming and identifiers.
- How does the smart grid influence energy management?
- Which are the best design principles for IoT application development?
- The best human-device interactions for the Internet of Things.
- The relation between urban dynamics and crowdsourcing services.
- The best wireless sensor network for IoT security.
- The best intrusion detection in IoT.
- The importance of big data on the Internet of Things.
Big Data Database Research Topics You Should Try
Big data is broad and interesting. These big data database research topics will put you in a better place in your research. You also get to evaluate the roles of various phenomena.
- The best cloud computing platforms for big data analytics.
- The parallel programming techniques for big data processing.
- The importance of big data models and algorithms in research.
- Evaluate the role of big data analytics for smart healthcare.
- How is big data analytics used in business intelligence?
- The best machine learning methods for big data.
- Evaluate the Hadoop programming in big data analytics.
- What is privacy-preserving to big data analytics?
- The best tools for massive big data processing
- IoT deployment in Governments and Internet service providers.
- How will IoT be used for future internet architectures?
- How does big data close the gap between research and implementation?
- What are the cross-layer attacks in IoT?
- The influence of big data and smart city planning in society.
- Why do you think user access control is important?
Big Data Scala Research Topics
Scala is a programming language that is used in data management. It is closely related to other data programming languages. Here are some of the best scala questions that you can research.
- Which are the most used languages in big data?
- How is scala used in big data research?
- Is scala better than Java in big data?
- How is scala a concise programming language?
- How does the scala language stream process in real-time?
- Which are the various libraries for data science and data analysis?
- How does scala allow imperative programming in data collection?
- Evaluate how scala includes a useful REPL for interaction.
- Evaluate scala’s IDE support.
- The data catalog reference model.
- Evaluate the basics of data management and its influence on research.
- Discuss the behavioral analytics process.
- What can you term as the experience economy?
- The difference between agile data science and scala language.
- Explain the graph analytics process.
Independent Research Topics for Big Data
These independent research topics for big data are based on the various technologies and how they are related. Big data will greatly be important for modern society.
- The biggest investment is in big data analysis.
- How are multi-cloud and hybrid settings deep roots?
- Why do you think machine learning will be in focus for a long while?
- Discuss in-memory computing.
- What is the difference between edge computing and in-memory computing?
- The relation between the Internet of things and big data.
- How will digital transformation make the world a better place?
- How does data analysis help in social network optimization?
- How will complex big data be essential for future enterprises?
- Compare the various big data frameworks.
- The best way to gather and monitor traffic information using the CCTV images
- Evaluate the hierarchical structure of groups and clusters in the decision tree.
- Which are the 3D mapping techniques for live streaming data.
- How does machine learning help to improve data analysis?
- Evaluate DataStream management in task allocation.
- How is big data provisioned through edge computing?
- The model-based clustering of texts.
- The best ways to manage big data.
- The use of machine learning in big data.
Is Your Big Data Thesis Giving You Problems?
These are some of the best topics that you can use to prosper in your studies. Not only are they easy to research but also reflect on real-time issues. Whether in University or college, you need to put enough effort into your studies to prosper. However, if you have time constraints, we can provide professional writing help. Are you looking for online expert writers? Look no further, we will provide quality work at a cheap price.

Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Comment * Error message
Name * Error message
Email * Error message
Save my name, email, and website in this browser for the next time I comment.
As Putin continues killing civilians, bombing kindergartens, and threatening WWIII, Ukraine fights for the world's peaceful future.
Ukraine Live Updates
Chapman University Digital Commons
Home > Dissertations and Theses > Computational and Data Sciences (PhD) Dissertations
Computational and Data Sciences (PhD) Dissertations
Below is a selection of dissertations from the Doctor of Philosophy in Computational and Data Sciences program in Schmid College that have been included in Chapman University Digital Commons. Additional dissertations from years prior to 2019 are available through the Leatherby Libraries' print collection or in Proquest's Dissertations and Theses database.
Dissertations from 2024 2024
Machine Learning and Geostatistical Approaches for Discovery of Weather and Climate Events Related to El Niño Phenomena , Sachi Perera
Dissertations from 2023 2023
Computational Analysis of Antibody Binding Mechanisms to the Omicron RBD of SARS-CoV-2 Spike Protein: Identification of Epitopes and Hotspots for Developing Effective Therapeutic Strategies , Mohammed Alshahrani
Integration of Computer Algebra Systems and Machine Learning in the Authoring of the SANYMS Intelligent Tutoring System , Sam Ford
Voluntary Action and Conscious Intention , Jake Gavenas
Random Variable Spaces: Mathematical Properties and an Extension to Programming Computable Functions , Mohammed Kurd-Misto
Computational Modeling of Superconductivity from the Set of Time-Dependent Ginzburg-Landau Equations for Advancements in Theory and Applications , Iris Mowgood
Application of Machine Learning Algorithms for Elucidation of Biological Networks from Time Series Gene Expression Data , Krupa Nagori
Stochastic Processes and Multi-Resolution Analysis: A Trigonometric Moment Problem Approach and an Analysis of the Expenditure Trends for Diabetic Patients , Isaac Nwi-Mozu
Applications of Causal Inference Methods for the Estimation of Effects of Bone Marrow Transplant and Prescription Drugs on Survival of Aplastic Anemia Patients , Yesha M. Patel
Causal Inference and Machine Learning Methods in Parkinson's Disease Data Analysis , Albert Pierce
Causal Inference Methods for Estimation of Survival and General Health Status Measures of Alzheimer’s Disease Patients , Ehsan Yaghmaei
Dissertations from 2022 2022
Computational Approaches to Facilitate Automated Interchange between Music and Art , Rao Hamza Ali
Causal Inference in Psychology and Neuroscience: From Association to Causation , Dehua Liang
Advances in NLP Algorithms on Unstructured Medical Notes Data and Approaches to Handling Class Imbalance Issues , Hanna Lu
Novel Techniques for Quantifying Secondhand Smoke Diffusion into Children's Bedroom , Sunil Ramchandani
Probing the Boundaries of Human Agency , Sook Mun Wong
Dissertations from 2021 2021
Predicting Eye Movement and Fixation Patterns on Scenic Images Using Machine Learning for Children with Autism Spectrum Disorder , Raymond Anden
Forecasting the Prices of Cryptocurrencies using a Novel Parameter Optimization of VARIMA Models , Alexander Barrett
Applications of Machine Learning to Facilitate Software Engineering and Scientific Computing , Natalie Best
Exploring Behaviors of Software Developers and Their Code Through Computational and Statistical Methods , Elia Eiroa Lledo
Assessing the Re-Identification Risk in ECG Datasets and an Application of Privacy Preserving Techniques in ECG Analysis , Arin Ghazarian
Multi-Modal Data Fusion, Image Segmentation, and Object Identification using Unsupervised Machine Learning: Conception, Validation, Applications, and a Basis for Multi-Modal Object Detection and Tracking , Nicholas LaHaye
Machine-Learning-Based Approach to Decoding Physiological and Neural Signals , Elnaz Lashgari
Learning-Based Modeling of Weather and Climate Events Related To El Niño Phenomenon via Differentiable Programming and Empirical Decompositions , Justin Le
Quantum State Estimation and Tracking for Superconducting Processors Using Machine Learning , Shiva Lotfallahzadeh Barzili
Novel Applications of Statistical and Machine Learning Methods to Analyze Trial-Level Data from Cognitive Measures , Chelsea Parlett
Optimal Analytical Methods for High Accuracy Cardiac Disease Classification and Treatment Based on ECG Data , Jianwei Zheng
Dissertations from 2020 2020
Development of Integrated Machine Learning and Data Science Approaches for the Prediction of Cancer Mutation and Autonomous Drug Discovery of Anti-Cancer Therapeutic Agents , Steven Agajanian
Allocation of Public Resources: Bringing Order to Chaos , Lance Clifner
A Novel Correction for the Adjusted Box-Pierce Test — New Risk Factors for Emergency Department Return Visits within 72 hours for Children with Respiratory Conditions — General Pediatric Model for Understanding and Predicting Prolonged Length of Stay , Sidy Danioko
A Computational and Experimental Examination of the FCC Incentive Auction , Logan Gantner
Exploring the Employment Landscape for Individuals with Autism Spectrum Disorders using Supervised and Unsupervised Machine Learning , Kayleigh Hyde
Integrated Machine Learning and Bioinformatics Approaches for Prediction of Cancer-Driving Gene Mutations , Oluyemi Odeyemi
On Quantum Effects of Vector Potentials and Generalizations of Functional Analysis , Ismael L. Paiva
Long Term Ground Based Precipitation Data Analysis: Spatial and Temporal Variability , Luciano Rodriguez
Gaining Computational Insight into Psychological Data: Applications of Machine Learning with Eating Disorders and Autism Spectrum Disorder , Natalia Rosenfield
Connecting the Dots for People with Autism: A Data-driven Approach to Designing and Evaluating a Global Filter , Viseth Sean
Novel Statistical and Machine Learning Methods for the Forecasting and Analysis of Major League Baseball Player Performance , Christopher Watkins
Dissertations from 2019 2019
Contributions to Variable Selection in Complexly Sampled Case-control Models, Epidemiology of 72-hour Emergency Department Readmission, and Out-of-site Migration Rate Estimation Using Pseudo-tagged Longitudinal Data , Kyle Anderson
Bias Reduction in Machine Learning Classifiers for Spatiotemporal Analysis of Coral Reefs using Remote Sensing Images , Justin J. Gapper
Estimating Auction Equilibria using Individual Evolutionary Learning , Kevin James
Employing Earth Observations and Artificial Intelligence to Address Key Global Environmental Challenges in Service of the SDGs , Wenzhao Li
Image Restoration using Automatic Damaged Regions Detection and Machine Learning-Based Inpainting Technique , Chloe Martin-King
Theses from 2017 2017
Optimized Forecasting of Dominant U.S. Stock Market Equities Using Univariate and Multivariate Time Series Analysis Methods , Michael Schwartz
- Collections
- Disciplines
Advanced Search
- Notify me via email or RSS
Author Corner
- Submit Research
- Rights and Terms of Use
- Leatherby Libraries
- Chapman University
ISSN 2572-1496
Home | About | FAQ | My Account | Accessibility Statement
Privacy Copyright
- How it works

Sample Masters Big Data Full Dissertation
Here is a sample that showcases why we are one of the world’s leading academic writing firms. This assignment was created by one of our expert academic writers and demonstrated the highest academic quality. Place your order today to achieve academic greatness.
View a different grade
Investigating the Impact of Big Data on Automobile Industry Operations
The current study uses a quantitative research approach to analyze how Big Data initiatives impact the operation functions of automobile companies in the UK. The research used a survey as the research instrument to gather data from 132 participants working in automobile companies in the UK. The survey looked to examine the opinions that executives had held about Big Data and how it impacted the company. The survey was distributed online to individuals that worked for automobile companies in the UK using Survey Monkey. The data obtained were then analyzed using descriptive statistics to find factors that may be influencing the use of Big Data in automobile companies. Based on these results, it is concluded that more significant investments in Big Data bring about positive impacts. The results presented conclude that investing more than 1 billion GBP on Big Data initiatives would provide greater tangible benefits for a business and positively impact the company. The results also found that companies with greater analytical abilities on the adequate and above adequate range could see measurable results. In the end, Big Data did have a positive and large impact on the operations business function of automobile companies.
Chapter 1: Introduction to the Research Topic
Introduction.
Big Data is recently on the rise as imperative information and tools need to be incorporated into businesses and daily life. Pflugfelder (2013) defines Big Data as large in volume, high in velocity, extensive in its variety, unable to be handled using conventional systems like relational databases, and needs unique and advanced technology for storage management analysis and visualization. However, the actual definition of Big Data varies from industry to industry and business to business. Schroeck et al. (2012) found in their research that 18 percent of businesses defined Big Data as a vast source of information, 15 percent of companies named it as real-time information, and seven percent of these businesses considered Big Data as a source of information from social media. By combining these demarcations, the resultant is a definition that portrays Big Data as a source of information that can be structured, unstructured, and semi-structured, which needs new technology, tools, and techniques for its storage, processing, analysis, and visualization for a large volume of data that is emitted at high speed and variety.
Significance of the Research Area
The automobile industry is increasingly becoming competitive in sustaining economies, especially with fierce competition between Western and Eastern manufacturers (Wallner and Kriglstein 2013). The industry has had a significant impact on regional and world economies and societies (Lee et al., 2014). To capture a large chunk of the market and consumers’ interest in an increasingly competitive market, it is crucial to make decisions based on real-time data. For this reason, many automobile companies around the world have begun to integrate Big Data into their decision-making process that ranges from manufacturing to marketing. Walker (2015) has found that integrating Big Data into business-related tasks in the automobile industry can be accomplished through the following; • Recalculating entire risk assortments within minutes • Identifying fraudulent behaviour quickly, which might affect the automobile industry. • Regulating root causes of problems, issues, failures, and defects could affect the longer term and shorter term. • Generating sales based on market research of consumer behaviour. With automobiles being an intricate part of developed society, it becomes mandatory for companies to ensure that they are providing quality products for the masses. Big Data can play a significant role in the business activities of automobile companies. With changing consumer behaviour and more informed consumers, it has become essential for companies to integrate real-time information into business decisions.
Problem Statement
Automobile manufacturing in the UK has become a vital part of its economy. According to the Society of Motor Manufacturers and Traders (2016), there were 2.63 million cars registered in 2015, which increased six percent from 2014. Due to the rapid changes and developments in the automobile industry, Big Data analysis has become vital to ensure new success levels in this revolutionary period. For this reason, the current study looks to understand the significance that Big Data plays in the Automobile industry. To compete in an already competitive environment, it has become necessary for businesses to understand the value that Big Data can bring to them. This makes it imperative for Big Data users to make decisions that can bring a competitive edge to the business, or else integrating Big Data becomes of use now. Schroeck et al. (2012) find that a vast deal of available data to companies is commonly unrelated. It comes from various data sources such as sensors, mobiles, transactions, social medial, log files, audio, video, images, and emails. The processing of such large amounts of data to produce meaningful decisions has become critical for businesses to thrive and succeed in markets where consumer trends cannot change rapidly (Shah et al., 2014). The automobile industry in the UK needs to improve its decision-making process to advance critical operations to compete in a highly competitive regional and international market. Monaghan (2016) notes that the British car industry has been enjoying prolonged periods of growth, as witnessed with a car production increase in June 2016 that rose by 10.4% to 159,000 cars, the highest since June 1998. According to the Society of Motor Manufacturers and Traders (SMMT), by 2017, the UK has the possibility of building a record number of vehicles per year that may overtake France and Spain to become Europe’s second-largest producer after Germany (Foy 2014). However, Foy (2014) points that such success may be hindered due to the eroding supply chain and operations of the British car industry, primarily smaller companies that provide parts and electronic components that go into cars, making it the biggest concern of the industry. To overcome these concerns, many are looking towards including more efficient data that may help industry leaders make better decisions for more prosperous businesses (Shooter 2013).
Research Aim and Objectives
Big Data is now widely being used in the automobile industry to take quick actions, saving time and cost prices. Understanding how the automobile industry can integrate the analysis of Big Data into its daily operations has become imperative to improve its integration and ensure that Big Data is being used correctly to obtain the maximum benefit from it. Therefore, the following research question has been formulated.
How has Big Data Impacted the UK Automobile Industry’s Operations?
Based on the research question, the research’s main aim is to investigate the impact of Big Data on the automobile industry, specifically in the UK, operations such as sales, customer retention, the manufacturing process, performance, marketing, logistics, and supply chain management. To achieve the research aim and answer the research question, the following objectives have been developed. • Assess the impact of Big Data on sales of automobiles and their marketing. • Assess the impact Big Data has on ensuring customer retention. • Examine how Big Data has revolutionized the automobile industry in the Uk and increased the potential use for business analytics. • Assess the impact that Big Data can have on improving the performance and efficiency of an automobile company.
Research Approach
The current study will be conducted using a qualitative research approach. Based on the sections above, the study’s aim and objectives have been developed to pursue the study’s research question using the proposed research approach. To build a research approach, a literature review was conducted to understand previous studies that have attempted to analyze Big Data’s influence in various industries. The results of the literature review (i.e., chapter two) aided in building the research approach. Under this approach, primary research is conducted using semi-structured interviews as the research instrument for data collection. The justification of this approach will be discussed in detail in chapter three of the study.
Project Outline
The current study is divided into six chapters. Below is the outline of the study;

Big Data has been influential in the 21st century by providing industries and companies with detailed information to make more intelligent business decisions. Very little research has been conducted on how Big Data impacts the automobile industry. Therefore, the current study aims to analyze and comprehend how Big Data impacts the UK automobile industry in influencing operations, sales, marketing, and other business aspects. For this purpose, the study developed a set of objectives that will be used to fulfil the study’s aim and the primary research question. The study is structured according to a qualitative research approach. Building the research approach designated the need for a literature review presented in the next chapter (i.e., Chapter two).
Chapter 2: Literature Review
The literature review chapter is constructed based on systematic research principles to provide an in-depth analysis of previously published literature on topics related to the current research. The literature review will provide critical insight into various definitions relevant to developing the current research and its primary focus throughout the dissertation. To conduct this literature review, it was essential to search for relevant papers through various databases such as Wiley Online Library, Science Direct, IEEE Xplore Digital Library, and Google Scholar. For the current literature review, the chapter is divided into sections that answer the literature reviews research questions, which are as follows;
- How to have various other fields and domains, other than the automobile industry, used Big Data analytics and visual analytics?
- What are the types of data sources that have been reported in the literature?
- What are types of Big Data visualization techniques and tools for Big Data visual analytics?
Previous literature that can provide understanding based on these questions was included in the literature review. Based on the analysis of the literature included, the methodology of the current research will be constructed.
The 7V’s of Big Data
Big Data is defined using the 7V’s known as volume, velocity, variety, variability, veracity, visualization, and value.

Figure 2.2-1: 7V’s of Big Data

Fields and Domains using Big Data and Visual Analytics
Based on the literature review, there are practically little to no publications available that portray the extent or detailed use of Big Data analytics in the automobile industry. However, many vital publications have noted that Big Data analytics is becoming a trend impacting businesses globally. Wozaniak et al. (2015) examined and determined to comprehend the type of data available to Volvo and how it was extracting such data. Based on the study, it is found that Volvo used data from its production planes and service centres to obtain data about their vehicles to assess information such as customer satisfaction, mileage coverage, and other vital factors that would improve decision making. Wozniak et al. (2015) found that Volvo uses data sources from logged production information; product specifications, client information, dealer information, product session information, telematics data, service history, repair history, warranties, and service contracts, which are then dispersed throughout the organization to specific departments, software teams, and engineers to use the data for production or operations improvements. Many other industries are also using Big Data analytics for their services and products.
Big Data analytics can have a profound impact on the future of banking industries. Collecting data at a massive scale can allow banks to comprehend the needs and expectations of their customers. However, banks lack the skills to execute and deploy significant data initiatives as they leverage more familiar technologies and software-development lifecycle (SDLC) methodologies. To develop analytic tools that experts in the banking industry comprehend, it is essential to meld together accurate data interpretation on a user-friendly interface. Commotion is an example of a Big Data analytics tool that keeps the user in mind. Commotion allows for a comfortable and easy experience for bank data exploration (Laberge, Anderson, et al., 2012). The analytics tool will enable analysts to drag and drop data collections that produce variable chart visualizations. The process is formally known as the “think loop process,” allowing analysts to dig and separate larger data collections to explore particular hypotheses based on smaller groupings to understand banks’ network anomalies (Laberge, Anderson, et al., 2012).
Implementing Big Data into the transportation industry has allowed it to become resilient in extreme scenarios. A large portion of the world’s population has shifted to urban living areas requiring cities to deliver sustainable, effective, and efficient services. Big data analytic research projects are currently commenced in the transportation industry to deal with massive data coming from roads & vehicle sensors, GPS devices, customer apps, and other websites. Ben Ayed et al. (2015) have reported using Big Data analytics in Dublin to improve the city’s public bus transportation network and reduce issues with increased traffic congestion. Using advanced analytics on the collected data, specific traffic problems were identified. The optimal time needed to start bus lanes was answered, and recommendations were made to add bus lanes (Ayed et al., 2015).
Ferreira, Poco et al.’s 2013 study provides insight into taxi trips to visually query taxi trips allowing taxi companies to make better decisions to schedule driver shifts and increase revenue. The use of Big Data analytics in transportation has also allowed policymakers to develop improved preparation plans and disaster management plans for high-risk events such as accidents, public gatherings, and natural disasters. Using smart card data and social media data, the resilience of transportation systems can be increased by analyzing changes in passenger behaviour, replaying historical events within the specific area to discover anomalous situations, and customer service (Itoh, Yokoyama, et al. 2014).
Types of Big Data Sources
Unlike typical data, Big Data contains videos, text, audio, images, and other forms of data collected from numerous datasets making it difficult to process with traditional database management tools giving rise to a new generation of tools specifically designed to analyze and visualization Big Data.
Santourian et al. (2014) observe that Big Data is often generated from transactions (i.e., invoices, payment orders, delivery records, and storage records) or unstructured data such as text extracts from websites, social media, or images.
However, Santourian et al. (2104) note that Big Data can also be collected in “real-time” from sensors such as those found in smartphones or from logs extracted from behaviour found online.
Big Data’s rawness due to the velocity by which it is being received oftentimes is unable to serve a statistical purpose as they have been collected by third parties who don’t emphasize data collection.
Big Data sources vary across industries as data collection needs to fit the purpose for they are to be used in the analysis. For example, Fiore et al. (2015) use data sources that have been made available by project partners or made available through national and international agencies developing a more static setup for Big Data analysis.
This included sources of data coming from satellite imagery, remote sensing data, hyperspectral imagery, and climate data used to formulate a use case infrastructure to analyze climate change trends in Manaus, Brazil (Fiore et al., 2015).
A study conducted by Baciu et al. (2015) has reported that use of sources that vary across fields, such as extracting data from a website known as a Bright kite that collects data from 4.5 million mobile users locations, such as their latitude and longitudes of each of the mobile users over specific intervals of time.
Studies that are less scientifically complex in theme use other sources of data; such as text sources which include words, phrases, and even entire documents extracted from social media platforms (i.e., Facebook) is used to analyze and predict events such as market trends, analyses product defects, and management of calamities (Fan and Gordon 2014; Mahmud et al. 2014).
Large companies also use various data sources to collect raw data to turn it into meaningful knowledge that can then be used to improve customer service, examine product defects, analyze organizational changes, and comprehend changing consumer trends (Heer and Kandel 2012; Kateja et al. 2014).
Volvo, an automobile manufacturer, uses data sources from logged product information; product specifications, client information, dealer information, product session information, telematics data, service history, repair history, warranties, and service contracts, which is then dispersed throughout the organization to specific departments/divisions, software teams, and engineers to use the data for improvements (Wozniak et al. 2015).
Big Data Visualization Techniques and Tools for Big Data Visual Analytics
Vatrapu et al. (2015) define data visualization as a method to communicate and transfer information clearly and effectively through graphical means. Given the rise of Big Data, analysts have begun to use data visualization methods to visualize, recognize, differentiate, interpret, and communicate configured data patterns based on the new visualization techniques specifically for massive datasets.
With new techniques, data scientists, analysts, and industry leaders benefit from comprehending massive amounts of data, recognizing emerging properties within the data, data quality control, feature detection on a small and large scale, and evidence for formulating hypotheses.
Generally, all visualization techniques and tools follow a similar pattern which includes the use of processing steps of data acquisition data transforming, mapping data onto visual models, and lastly, rendering or viewing the data (Zhang et al. 2013; Goonetilleke et al. Liu et al. 2015; Fu et al. 2014). Following is a brief discussion of visualization tools and techniques that have been used across diverse industries and studies to Big Data.
Popular domains that highly demand Big Data are healthcare, automobile, transport/Urban infrastructure, banking, and retail. The chapter also found sources through which the domains discussed retrieve vital information/data to use as meaningful knowledge. It is evident from the literature review that sources for retrieval of data diverge significantly from normal sources.
Firstly, the Big Data sources will contain massive data from sensors such as those on a phone that monitor health. With such massive data, it is necessary to follow specific steps laid out for Big Data analytics. Data analysis is done to the most microscopic level that a researcher can go with such tremendous amounts of data.
Finally, data visualization becomes necessary for producing information that can be used to help in decision-making.
A systematic literature review has also revealed the numerous different sources from which Big Data is extracted. Sources vary depending on the domain, which is the source to extract specific kinds of data.
Literature reveals that typical Big Data contains videos, texts, audio, and images at massive levels of datasets. The datasets’ complexity produces a challenge for traditional database management tools to handle the volume of the data that is being analyzed.
Familiar sources for Big Data generation are payment orders, delivery records, invoices, and storage records. However, sources can be “real-time” if it is collected by sensors such as those present in smartphones.
Unstructured data is also commonly seen in Big Data ranging from social media posts, images, text extracts from websites, or even whole websites. Regardless of what type of data it is, the sources from which it is obtained will vary from industry to industry.
Data can come from social media data such as Facebook wall posts, comments, likes, and Twitter tweets, to name a few. Simultaneously, more experimental and scientific sources also provide specific data such as temperature, humidity, and wind speeds data in “real-time” to analyze and make predictions towards climate change.
Hire an Expert Dissertation Writer
Orders completed by our expert writers are
- Formally drafted in the academic style
- 100% Plagiarism-free & 100% Confidential
- Never resold
- Include unlimited free revisions
- Completed to match exact client requirements

Chapter 3: Conceptual Framework
The chapter presents the conceptual framework for automobile company executives to adopt. This is achieved using the adopters’ category under the diffusion of innovations theory proposed by Rogers (2003).
Theoretical Development
The diffusion of innovations theory was heavily relied upon to develop the conceptual framework, as Rogers (2003) proposed. Based on the idea, diffusion is the process by which innovation is communicated over some time among those participating in a social system. According to Rogers (2003), four main elements influence the spread of a new idea; innovation, communication channels, time, and a social system. Currently, automobile companies are slowly creeping into Big Data to handle operations, as evident from the literature review. The process of diffusion relies extremely on human capital. This means that innovation needs to be widely adopted within a setting to self-sustain itself.
There are various strategies available to help an innovation reach the stage of critical mass. This includes the strategy of when an innovation is adopted by a highly respective person in an organisation and develops an instinctive desire for a specific innovation. Rogers (2003) argues that one of the best strategies is to place innovation into a group of individuals who can readily use the technology and provide positive reactions resulting in benefits to early adopters. By using the adoption process under innovation theory diffusion, automobile companies can target respected high-level executives to shift their support towards big data initiatives.
The proposed conceptual framework provides automobile companies with strategies that adopt big data initiatives to promote innovation. The best way to do so is to present innovation to highly respectable executives in the company to promote innovation to self-sustain it.
Chapter 4: Methodology
The current chapter presents developing the research methods needed to complete the experimentation portion of the current study. The chapter will discuss in detail the various stages of developing the methodology of the current study. This includes a detailed discussion of the philosophical background of the research method chosen. In addition to this, the chapter describes the data collection strategy, including a selection of research instrumentation and sampling. The chapter closes with a discussion on the analysis tools used to analyse the data collected.
Selecting an Appropriate Research Approach
Creswall (2013) stated that research approaches are plans and procedures that range from making broad assumptions to detailed methods of data collection, analysis, and interpretation.
The several decisions involved in the process are used to decide which approach should be used in a specific study that is informed using philosophical assumptions brought to the study (Creswall 2013).
These are procedures of inquiry or research designs and specific research methods used for data collection, its analysis, and finally, its interpretation. However, Guetterman (2015); Lewis (2015); and Creswall (2013) argue that the selection of the specific research approach is based on the nature of the research problem, or the issue that is being addressed by any study, personal experiences of the researchers’, and even the audience for which the study is being developed for.
The main three categories with which research approaches are organised include; qualitative, quantitative, and mixed research methods. Creswall (2013) comments that all three approaches are not considered discrete or distinct.
Creswall (2013) states, “qualitative and quantitative approaches should not be viewed as rigid, distinct categories, polar opposite, or dichotomies” (p.32).
Guetterman (2015) points out that a clearer way of viewing gradations of differences between the approaches is to examine the basic philosophical assumptions brought to the study, the kinds of research strategies used, and the particular methods implemented in conducting the strategy.
Underlying Philosophical Assumptions
An important component of defining the research approach involves philosophical assumptions that contribute to the broad research approach of planning or proposing to conduct research. It involves the intersection of philosophy, research designs, and specific methods, as illustrated in Fig. 1 below.

Figure 4.2-1- Research Onion (Source; Saunders and Tosey 2013)
Saunders et al. (2009) define research philosophy as a belief about how data about a phenomenon should be gathered, analyzed, and used. Positivism reflects the acceptance in adopting the philosophical stance of natural scientists (Saunders, 2003).
According to Remenyi et al. (1998), there is a greater preference in working with an “observable social reality” and that the outcome of such research can be “law-like” generalisations that are the same as those which physical and natural scientists produce.
Gill and Johnson (1997) add that it will also emphasise a highly structured methodology to replicate other studies. Dumke (2002) agrees and explains that a positivist philosophical assumption produces highly structured methods and allows for generalisation and quantification of objectives that statistical methods can evaluate.
For this philosophical approach, the researcher is considered an objective observer who should not be impacted by or impact the research subject.
The current study chooses positivist assumptions due to the literature review’s discussion of the importance of Big Data in industrial domains and the need to measure its success in business operations.
To identify a positive relationship between Big Data usage and beneficial business outcomes, the theory needs to be used to generate hypotheses that can later be tested of the relationship, which would allow for explanations of laws that can thereafter be assessed (Bryman and Bell, 2015).
Selecting Interpretive Research Approach
Interpretive research approaches are derived from the research philosophy that is adopted. According to Dumke (2002), the two main research approaches are deductive and inductive.
The inductive approach is commonly referred to when theory is derived from observations. Thus, the research begins with specific observations and measures. It is then from detecting some pattern that a hypothesis is developed.
Dumke (2002) argues that researchers who use an inductive approach usually work with qualitative data and apply various methods to gather specific information that places different views.
From the philosophical assumptions discussed in the previous section, it is reasonable to use the deductive approach for the current study. It is also considered the most commonly used theory to establish a relationship between theory and research. The figure below illustrates the steps used for the process of deduction.

Figure 4.2-2- The process of deduction (Source, Bryman and Bell 2015)
Based on what is known about a specific domain, the theoretical considerations encompassing it a hypothesis or hypotheses are deduced that will later be subjected to empirical inquiry (Daum, 2013). Through these hypotheses, concepts of the subject of interest will be translated into rational entities for a study. Researchers are then able to deduce their hypotheses and convert them into operational terms.
Justifying the Use of Quantitative Research Method
Saunders (2003) notes that almost all research will involve numerical data or even contain data quantified to help a researcher answer their research questions and meet the study’s objectives.
However, quantitative data refers to all data that can be a product of all research strategies (Bryman and Bell, 2015; Guetterman, 2015; Lewis, 2015; Saunders, 2003).
Based on the philosophical assumptions and interpretive research approach, a quantitative research method is the best suited for the current study. Mujis (2010) defends the use of quantitative research because, unlike qualitative research, which argues that there is no pre-existing reality, quantitative assumes that there is only a single reality about a social condition that researchers cannot influence way.
Selecting an Appropriate Research Strategy
There are many strategies available to implement in a study, as evidence by Fig. 1. There are many mono-quantitative methods, such as telephone interviews, web-based surveys, postal surveys, and structured questionnaires (Haq 2014).
Each instrument has its own pros and cons in terms of quality, time, and data cost. Brymand (2006); Driscoll et al. (2007); Edwards et al. (2002); and Newby et al. (2003) note that most researchers use structured questionnaires for data collection they are unable to control or influence respondents, which leads to low response rates but more accurate data obtained.
Saunders and Tosey (2015) have argued that quantitative data is simpler to obtain and more concise to present. Therefore, the current study uses a survey-based questionnaire (See Appendix A).
Justifying the use of Survey Based Questionnaire
Surveys are considered the most traditional forms of research and use in non-experimental descriptive designs that describe some reality. Survey-based questionnaires are often restricted to a representative sample of a potential group of the study’s interest.
In this case, it is the executives currently working for automobile companies in the UK. The survey instrument is then chosen for its effectiveness at being practical and inexpensive (Kelley et al., 2003).
The philosophical assumptions, interpretive approach, and methodological approach are chosen. The current study’s survey design is considered the best instrument in line with these premises and cost-effectively.
Empirical Research Methodology
Research design.
This section describes how research is designed to use the techniques used for data collection, sampling strategy, and data analysis for a quantitative method. Before going into the strategies of data collection and analysis, a set of hypotheses were developed.
Hypotheses Development

Data Collection
This section includes the sampling method used to collect the number of respondents needed to provide information then analysed after collection.
Sampling Method
Collis (2009) explains that there are many kinds of sampling methods that can be used for creating a specific target sample from a population. This current study uses simple random sampling to acquire respondents with which the survey will be conducted.
Simple random sampling is considered the most basic form of probability sampling. Under the method, elements taken from the population are random, with all elements having an equal chance of being selected.
According to the Office of National Statistics (ONS), as of 2014, there are about thirty-five active British car manufacturers in the UK, each having an employee population of 150 or more.
This is why the total population of employees in car manufacturers is estimated to be 5,250 employees. The sample therefore developed, used the following equation;

Where; N is the population size, e is a margin of error (as a decimal), z is confidence level (as a z-score), and p is percentage value (as a decimal). Thus, the sample size is with a normal distribution of 50%. With the above equation, a population of 5,250, with a 95% confidence level and 5% margin of error, the total sample size needed for the current equals 300. Therefore, N=300 is the sample size of the current study.
The survey development (see Appendix A) has a total of three sections, A, B, and C, with a total of 39 questions. Each section has its own set of questions to accomplish.
The survey is a mix of closed-ended questions that comprehend the respondent’s demographic make us, the Big Data initiatives of the company, and the impact that Big Data was having in their company. The survey is designed to take no longer than twenty minutes. The survey was constructed on Survey Monkey.com, an online survey-provided website.
The survey was left on the website for a duration of 3.5 weeks to ensure that a maximum number of respondents answered the survey. The only way the survey was allowed for a respondent is to pass a security question that asks if they are working for an automobile company in the UK to take the survey.
Gupta et al. (2004) believe that web surveys are visual stimuli, and the respondent has complete control concerning whether or how each question is read and understood. That is why Dillman (2000) argued that web questionnaires are expected to resemble those taken through the mail/postal services closely.
Data Analysis
The collected data is then analysed using the Statistical Package for Social Science (SPSS) version 24 for descriptive analysis. The demographic section of the survey will be analysed using descriptive statistics. Further analysis of the data also includes the use of descriptive statistics.
Conclusions
The chapter provides a descriptive and in-depth discussion of the methods involved in the current study’s research. The current study looks towards a quantitative approach that considers positivism as its philosophical undertaking, using deductive reasoning for its interpretive approach, a mono-quantitative method that involves using a survey instrument for data collection.
The methodology chapter also provided the data analysis technique, which is descriptive statistics through frequency analysis and regression analysis.
Chapter 5 Results and Analysis
The chapter provides the findings of the current study based on the survey results obtained. It provides a straightforward statement of the results using descriptive statistics, which would later be further analysed using SPSS v.24 software. The need for SPSS is to conduct a regression analysis to provide a detailed examination of the data.
Section A- Demographic Results
The study had called for 300 respondents to answer the survey using Survey Monkey, left online for 3.5 weeks. However, the total completed surveys obtained was 132, making the survey’s response rate only forty-four percent (44%). It was not the best response rate, but it still provided a broad range of participants to analyse.
The first question of the survey’s section A called for respondents to identify their job title for the current automobile company that they were working for. Fig. 5.2-1-1 shows that operations managers and supervisors made up the greatest number of respondents in the study.
Operations managers had composed 14 percent of the respondents, followed by the foreperson, supervisor, lead person of 13 percent, and the project managers that made 12 percent of the respondents.

Respondents were also asked to indicate the number of years they have been employed in a specific organisation. Allowing for such insight would provide a sense of experience that the participant may have had while working in the company.

Figure 5.2-2.- How long have you worked for the organization?
This is illustrated in Fig. 5.2-2, in which 42 percent of respondents have indicated that they have worked for the company for five to ten years. Of the respondents, thirty-three percent have indicated that they have worked for their company for 10-15 years, while thirty percent indicated less than five years. The remaining 27 percent indicated employment for over fifteen years.
The survey also asked respondents to indicate the number of employees who worked for the firm ty was employed in. Having such knowledge would allow the researcher to understand the extent of operations conducted in the automobile company. Having such an understanding provides insight into the scope of use in Big Data being implemented in the company (see Fig.5.2-3).

Figure 5.2-3- How many people are employed in the organization you work for?
A total of 46.97 percent of respondents indicated that they worked for companies that employed 50 to 250 employees. Also, 35.61 percent of employees indicated that they were employed by companies with more than 250 employees working for them.
Lastly, 17.42 percent of respondents indicated that the companies they worked for had 10-15 employees. Many respondents indicated that they worked for companies with more than 50 employees, indicating that the companies included in the study are small-to-medium businesses and large enterprises.

Figure 5.2-4 – Does your company use Big Data analytics?
Of the respondents participating, 72.73 percent indicated that their company was using Big Data analytics. This was crucial as it provided insight into the number of automobile companies with Big Data analytic systems.
As seen in Fig. 5.2.-5, only eighty-one (81) respondents from 132 had direct exposure to Big Data to either analyse, visualise, or make business decisions based on it. The pool of respondents was considerably smaller than anticipated.
Still, these slight details will provide greater insight into automobile companies’ workings regarding their use or integration of Big Data into the company. Based on the demographic analysis, participants who completed their survey had some access to Big Data analysis. But there is still a large group of people in these companies that do not have any exposure or access to Big Data.

Figure 5.2-5 – Have you ever been exposed to using any form of Big Data in terms of analyzing it, visualizing it, or making decisions based on it?
Section B & C- Company Big Data Initiative and Impacts Results
The next section of the questionnaire, section B, aimed to analyse the respondent’s answers to identify the extent of integration or implementation of Big Data initiatives in the automobile company they worked for.
This section aims to understand the extent to which Big Data is present in automobile companies. This information can compare with the next team, which looks to understand and examine the effects of big data initiatives in the company.
Fig. 5.3-1 illustrates the main issues that may have caused the automobile company to implement Big Data initiatives. Based on the graph, it is concluded that analysing streaming data and data sets greater than 1 Terabyte (TB) were the greatest cause of initiating Big Data into the company, as per the response of 19.70 percent of respondents, respectively.

Figure 5.3-1- What were the organization’s primary data issues that led it to consider Big Data?
Another issue that instigated Big Data analytics in companies was analysing data sets from 1 TB to 100 TB, as indicated by 18.18 percent of respondents. Next in the rank was analysing new data types, which led to using Big Data analytics as indicated by 13.64 percent of respondents.
Fig. 5.3-2 illustrates the reaction of respondents to two questions.
- Questions 2. How would you rate the analytical abilities of the company you are employed in?
- Question 5. How would you rate the access to relevant, accurate, and timely data in your company today?

Figure 5.3-2 – How would you rate the analytical abilities of the company you are employed in? How would you rate the access to relevant, accurate, and timely data in your company today?
There is a strong correlation between access to Big Data and the analytical abilities of the company. Based on the illustration, 55 people who had access to Big Data thought the access was adequate, with 42 of them believing that its analytical ability was adequate. Furthermore, 69 participants indicated that access to Big Data was more than adequate, with 57 participants believing that the firm’s analytical ability was more than adequate. It can be concluded that the greater the access to Big Data, the adequate or more adequate the analytical abilities of the firm.
The next graph indicates the amount of spending that is placed on a Big Data initiative’s budget. Oftentimes, it was seen, as from the literature review, that funding Big Data analytics in a company allowed for greater business gains. Therefore, it was essential to understand the budget amount that was invested in Big Data initiatives.
A majority of respondents, about 47 percent, indicated that their company had a Big Data initiative budget of £1 million to GBP 10 million. Another 40 percent of respondents have indicated that their company spent £100,000 to GBP 1 million on their Big Data systems.
The amount of staff dedicated to Big Data analytics is also thought to play a part in advancing the goals that may be set for an automobile company regarding Big Data. The figure below takes two questions;
Questions 7- Approximately how many staff in your company are dedicated to analytics, modelling, data mining (not including routine reporting)? Question 8- Of these staff, are you mostly working in or for your consumer-facing (B2C) businesses, your commercial or wholesale (B2B) businesses, or both?

Figure 5.3-4 Approximately how many staff in your company are dedicated to analytics, modeling, data mining (not including routine reporting)? Of these staff, are you mostly working in or for your consumer-facing (B2C) businesses, your commercial or wholesale (B2B) businesses, or both?
Based on the illustration, nineteen (19) respondents indicated that 501-1000 employees are dedicated to B2B and B2C analytics. Using Big Data analytics for both B2B and B2C comprises the most agreement of respondents, with 72 of 132 indicated so.

Figure 5.3-5 How does the company plan to measure the success of your Big Data initiatives?
The figure above represents the respondent’s answers to their automobile company’s plan for measuring Big Data’s success. Of the 132 participants, 44.70 percent responded that the company is planning on using quantitative metrics associated with business performance to analyse if Big Data is actually successful.
Another 30.30 percent indicated that their company was planning on using qualitative metrics tied to business performance. Using business performance to analyse Big Data’s success is coherent to the results of the literature review that indicated previous studies of doing such.
As an automobile company, they need to know the results of using Big Data analytics, and that is only by using business performance indicators regardless of being qualitative or quantitative.

Figure 5.3-6 Has the company achieved measurable results from its investments in Big Data?
Fig. 5.3-6 portrays the response of participants regarding achieving measurable results from Big Data. According to 68.18percentt of the respondents,s the company they worked for did indeed show measurable results from their Big Data investments.
However, 31.82 percent indicated that there was indeed no measurable result in investing in Big Data. Based on these results and those presented in 5.3-2, the results support H5, which states that a company’s analytical abilities allow for measurable results.

Figure 5.3-7: Impact of Big Data on Company
Fig. 5.3-7 presents the answers of respondents of the impact of Big Data on automobile companies. An estimate of 60% of participants indicated that Big Data initiatives had been started, and the company has benefited from a decrease in expenses.
This response, coupled with the responses seen in Fig. 5.3-3, supports hypothesis H2 that the greater company’s budget (>1million GBP) would decrease expenses.
Also, over 70% of respondents indicate that their companies had started and benefited from Big Data initiatives by monetising from the initiatives. These results, coupled with those presented in Fig. 5.3-3, supports H1, which suggested that larger investments (<1million GBP) would result in the company’s ability to monetise and generate new revenues.

Figure 5.3-8: Questions 11 & 12 11. Since the Big Data initiatives implemented, what tangible benefits have been achieved in the company? What are the tangible benefits the company is aiming to achieve using Big Data initiatives?
Fig. 5.3-8 presents the actual and projected benefits of Big Data initiatives. Over 60% of respondents indicated that their automobile company had witnessed actual benefits in increasing sales and product innovations since their Big Data initiatives.
Other benefits that overcame project benefits include improved customer experience, higher quality products/services, efficient operations, and improved decision making. Coupled with the results from 5.3-3, the data support hypotheses H6 and H8.

Figure 5.3-9: What business functions in the company are fueling Big Data initiatives?
Fig. 5.3-9 presents the results of question 13 in section C of the questionnaire. Respondents were asked which business function may be fueling the drive for Big Data initiatives.
The sample, 34.09%, indicated that operations were the main business function fueling Big Data in the company. After operations, the second-highest function is customer service, with 18.94% of respondents indicating this.
The business function thought to be the least influential in driving Big Data in automobile companies was Information Technology, with 9.09% indicating it.
The results of this partially support H7 because according to question 15 section C, 25% of respondents indicated that in the next five years, Big Data would impact and fundamentally change the way business is done in the organisation as opposed to 15.91% of respondents that indicated it would change the way the business will organise operations.
Based on the study results, hypotheses H1, H2, H5, H6, H8, and part of H7 have been supported. This leads to the conclusion that Big Data initiatives in automobile companies have had a significant impact on the company’s operations.
The companies have significantly benefited from increased sales, greater product innovations, improved customer care, and efficient decision-making. Greater investment of more than 1 billion GBP has led to better results obtained from Big Data initiatives.
If you need assistance with writing your dissertation, our professional dissertation writers are here to help!
Chapter 6: conclusion and discussion, research overview.
The current study aimed to analyze the impact that Big Data initiatives had on automobile companies in the UK, especially its operations. The current study was developed using a quantitative approach, which meant using philosophical assumptions from the positivist school of thought and producing a methodology that would follow deductive reasoning.
Under these assumptions, the quantitative approach was selected and used the survey instrument to gather data. This data was then analyzed using descriptive statistics to examine the results and link it to a set of proposed hypotheses.
The results presented conclude that investing more than 1 billion GBP on Big Data initiatives would provide greater tangible benefits for a business and positively impact the company.
The results also found that companies with greater analytical abilities on the adequate and above adequate range could see measurable results. In the end, Big Data did have a positive and large impact on the operations business function of automobile companies.
Meeting the Aim and Objectives of the Project
The research’s main aim was to investigate the impact of Big Data on the automobile industry, specifically in the UK, operations such as sales, customer retention, the manufacturing process, performance, marketing, logistics, and supply chain management.
The current study was able to accomplish this using the objectives. The study’s aims and objectives were supported by the revelation that the following hypotheses are supported by the results and analysis in Chapter 5.
H1- The greater the company’s budget for Big Data initiatives (More than 1 million GBP), the greater its ability to monetize and generate new revenues.
H2- The greater the company’s budget for Big Data initiatives (More than 1 million GBP), the greater decrease in expenses is found.
H5- The analytical abilities of a company allow for achieved measurable results.
H6- Investing in Big Data will lead to highly successful business results.
H7- A business’s operations function is fueling Big Data initiatives.
H8- The implementation of Big Data in the company has positive impacts on business.
Statement of Contributions and Research Novelty
Based on the literature review conducted in chapter 2, there is little to no academic research on Big Data’s impact on automobile companies. Due to this significant gap in research, the current study can contribute to literature using the insight provided by this study’s results.
The study analyzed how executives in automobile companies in the UK perceive the contributions made by Big Data in their companies. This insight can then be used to attract other researchers to study the phenomena. Big Data and its emergence in the current markets is fairly new, making the idea behind the current a novel idea.
Research Limitations
The research was severely limited due to the number of respondents being a lot less than those proposed; 300 respondents were needed; however, only 132 had completed the survey.
This may be because the survey was distributed online. This makes it difficult to tell how many people had seen the survey link but had not participated. The idea that the survey may have been too long, making respondents weary of answering the questions due to the great length of time it took to answer.
Due to the sample constraint, the results obtained from the current study cannot be generalized to the population sampled. It is recommended that other forms of distributing surveys be used to garner the maximum number of respondents.
There is also the inability of automobile companies to speak to researchers on the phone, which led to the drop in using interviews in the study. With interviews, a greater deal of insight can be brought to the results obtained from the survey. Complementing these would have made the results of the study more accurate and reliable.
Recommendations for Future Research
It is recommended that future studies take into account the loopholes of the current study. From the literature review, very little literature is available on the impact of Big Data on automobile companies.
Due to this lack, future researchers are encouraged to research this industry because drastic changes may result in increased use of Big Data. Future researchers are recommended to use a mixed-methods approach to obtaining and analyzing data.
With a mixed-methods approach, qualitative and quantitative data can complement each other to make assumptions stronger and test hypotheses in a highly effective manner.
Abusharekh, A., Stewart, S. A., Hashemian, N., Abidi, S. S. R. 2015. H-Drive: A big health data analytics platform for evidence-informed decision making. IEEE International Congress on Big Data, p. 416- 432.
Aihara, K., Imura, H., Takasu, A., Tanaka, Y., Adachi, J. 2014. Crowdsourced mobile sensing in smarter city life. IEEE 7th International Conference on Service-Oriented Computing and Applications, p. 334- 337.
Amelia, A., and Saptawati, G. A. P. 2014. Detection of potential traffic jams based on traffic characteristic data analysis. IEEE, p. 1- 5.
Bryman, A., Bell, E., 2015. Business Research Methods. Oxford University Press.
Cook, K., Grinstein, G., Whiting, M., Cooper, M., Having, P., Ligget, K., Nebesh, B., and Paul, C. L. 2012. VAST Challenge 2012: Visual Analytics for Big Data. IEEE Symposium on Visual Analytics Science and Technology 2012, p. 251- 257. Seattle, WA: Print.
Daum, P., 2013. International Synergy Management: A Strategic Approach for Raising Efficiencies in the Cross-border Interaction Process. Anchor Academic Publishing (aap_verlag).
Dümke, R., 2002. Corporate Reputation and its Importance for Business Success: A European Perspective and its Implication for Public Relations Consultancies. diplom.de.
Foy, H. 2014. UK’s resurgent car industry still faces challenges. Financial Times.
Guetterman, T.C., 2015. Descriptions of Sampling Practices Within Five Approaches to Qualitative Research in Education and the Health Sciences. Forum Qualitative Sozialforschung / Forum: Qualitative Social Research 16.
Haq, M., 2014. A Comparative Analysis of Qualitative and Quantitative Research Methods and a Justification for Adopting Mixed Methods in Social Research (PDF Download Available). ResearchGate 1–22. doi:http://dx.doi.org/10.13140/RG.2.1.1945.8640
Itoh, M., Yokoyama, D., Toyoda, M., and Tomita, Y. 2014. Visual fusion of Mega-City Big Data: An application to traffic and tweets data analysis of Metro passengers. IEEE International Conference on Big Data, p. 431-442.
Kerr, K., Hausman, B. L., Gad, S., and Javen, W. 2013. Visualization and rhetoric: key concerns for utilizing bid data in humanities research- A case study of vaccination discourse 1918-1919. IEEE International Conference on Big Data, p.25- 32.
Kelley, K., Clark, B., Brown, V., Sitzia, J., 2003. Good practice in the conduct and reporting of survey research. Int J Qual Health Care 15, 261–266. doi:10.1093/intqhc/mzg031.
Lee, J., Noh, G., Kim, C. K. 2014. Analysis & visualization of movie’s popularity and reviews. IEEE International Conference on Big Data, pp. 189-190.
Lewis, S., 2015. Qualitative Inquiry and Research Design: Choosing Among Five Approaches. Health Promotion Practice 16, 473–475. doi:10.1177/1524839915580941
Liu, D., Kitamura, Y., Zeng, X. 2015. Analysis and visualization of traffic conditions of the road network by route bus probe data. IEEE International Conference on Multimedia Big Data, p. 248-251.
Lorenzo, G. D., Sbodio, M. L., Calabrese, F., Berlongerio, M., Nair, R., and Pinelli, F. 2014. All aboard: Visual exploration of cellphone mobility data to optimize public transport. IUI Haifa, Israel, p. 335- 340. Print.
Monaghan, A. 2016. UK car manufacturing hits high but industry warns of Brexit effect. The Guardian. [online] < https://www.theguardian.com/business/2016/jul/28/uk-car-manufacturing-hits-high-industry-warns-brexit-effect >. [Accessed : 2017 March 2].
Pu, J., Liu, S., Qu, H., Ni, L. 2013. T-watcher: A new visual analytic system for effective traffic surveillance. IEEE 14th International Conference on Mobile Data Management, p. 127- 136.
Rysavy, S. J., Bromley, D., and Daggett, V. 2014. DIVE: A graph-based visual analytics framework for Big Data. Visual Analytics for Biological Data, IEEE Computer Graphics and Applications, p. 26-37.
Saunders, M., 2003. Research Methods for Business Students. Pearson Education India.
Saunders, M.N.K., Tosey, P., 2015. Handbook of Research Methods on Human Resource Development. Edward Elgar Publishing.
Shah, A. H., Gopalakrishnan, G., Rajendran, A., and Liebel, U. 2014. Data mining and sharing tool for high content screening large scale biological image data. IEEE International Conference on Big Data, p. 1068- 1076.
Steiger, E., Ellersiek, T., and Sipf, A. 2014. Explorative public transport flow analysis from uncertain social media data. SIGSPATAL, p. 1-7. Print.
Walker, R. 2015. From Big Data to Big Profits (1st ed.). Print.
Wallner, G., and Kriglstein, S. 2013. Visualization-based analysis of gameplay data- A review of the literature. Entertainment Computing, 4, pp. 143-155.
Wozniak, P., Valton, R., Fjeld, M. 2015. Volvo single view of vehicle: Building a Big Data service from scratch in the automotive industry. CHI: Crossings, Seoul, Korea, p. 671-678.
Xiao, S., Liu, C. X., Wang, Y. 2015. Data driven geospatial-enabled transportation platform for freeway performance. IEEE Intelligent Transportation Systems Magazine, p. 10-21.
Zhang, Z., Wang, S., Cao, G., Padmanabhan, A., and Wu, K. 2014. A scalable approach to extracting mobility patterns from social media data. National Science Foundation, p. 1-6. Print.
9 Appendix A- Survey
Please contact us to get access to the full Appendix Survey.
10 Appendix B- Raw Data
11 appendix c- responses job title x organization size.

12 Appendix D- Responses Question 2, 5, & 6

Frequently Asked Questions
How much time it takes to write a masters level full dissertation.
The time required to write a master’s level full dissertation varies, but it typically takes 6-12 months, depending on research complexity and individual pace.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works
M.Tech/Ph.D Thesis Help in Chandigarh | Thesis Guidance in Chandigarh

+91-9465330425

These days the internet is being widely used than it was used a few years back. It has become a core part of our life. Billions of people are using social media and social networking every day all across the globe. Such a huge number of people generate a flood of data which have become quite complex to manage. Considering this enormous data, a term has been coined to represent it. So, what is this term called? Yes, Big Data Big Data is the term coined to refer to this huge amount of data. The concept of big data is fast spreading its arms all over the world. It is a trending topic for thesis, project, research, and dissertation. There are various good topics for the master’s thesis and research in Big Data and Hadoop as well as for Ph.D. First of all know, what is big data and Hadoop?
Find the link at the end to download the latest thesis and research topics in Big Data
What is Big Data?
Big Data refers to the large volume of data which may be structured or unstructured and which make use of certain new technologies and techniques to handle it. An organized form of data is known as structured data while an unorganized form of data is known as unstructured data. The data sets in big data are so large and complex that we cannot handle them using traditional application software. There are certain frameworks like Hadoop designed for processing big data. These techniques are also used to extract useful insights from data using predictive analysis, user behavior, and analytics. You can explore more on big data introduction while working on the thesis in Big Data. Big Data is defined by three Vs:
Volume – It refers to the amount of data that is generated. The data can be low-density, high volume, structured/unstructured or data with unknown value. This unknown data is converted into useful one using technologies like Hadoop. The data can range from terabytes to petabytes. Velocity – It refers to the rate at which the data is generated. The data is received at an unprecedented speed and is acted upon in a timely manner. It also requires real-time evaluation and action in case of the Internet of Things(IoT) applications. Variety – Variety refers to different formats of data. It may be structured, unstructured or semi-structured. The data can be audio, video, text or email. In this additional processing is required to derive the meaning of data and also to support the metadata. In addition to these three Vs of data, following Vs are also defined in big data. Value – Each form of data has some value which needs to be discovered. There are certain qualitative and quantitative techniques to derive meaning from data. For deriving value from data, certain new discoveries and techniques are required. Variability – Another dimension for big data is the variability of data i.e the flow of data can be high or low. There are challenges in managing this flow of data.
Thesis Research Topics in Big Data
- Privacy, Security Issues in Big Data .
- Storage Systems of Scalable for Big Data .
- Massive Big Data Processing of Software and Tools.
- Techniques and Data Mining Tools for Big Data .
- Big Data Adoptation and Analytics of Cloud Computing Platforms.
- Scalable Architectures for Parallel Data Processing.
Can you imagine how big is big data? Of course, you can’t. The amount of big data that is generated and stored on a global scale is unbelievable and is growing day by day. But do you know, only a small portion of this data is actually analyzed mainly for getting useful insights and information?
Big Data Hadoop
Hadoop is an open-source framework provided to process and store big data. Hadoop makes use of simple programming models to process big data in a distributed environment across clusters of computers. Hadoop provides storage for a large volume of data along with advanced processing power. It also gives the ability to handle multiple tasks and jobs.
Big Data Hadoop Architecture
HDFS is the main component of Hadoop architecture. It stands for Hadoop Distributed File Systems. It is used to store a large amount of data and multiple machines are used for this storage. MapReduce Overview is another component of big data architecture. The data is processed here in a distributed manner across multiple machines. YARN component is used for data processing resources like CPU, RAM, and memory. Resource Manager and Node Manager are the elements of YARN. These two elements work as master and slave. Resource Manager is the master and assigns resources to the slave i.e. Node Manager. Node Manager sends the signal to the master when it is going to start the work. Big Data Hadoop for the thesis will be plus point for you.
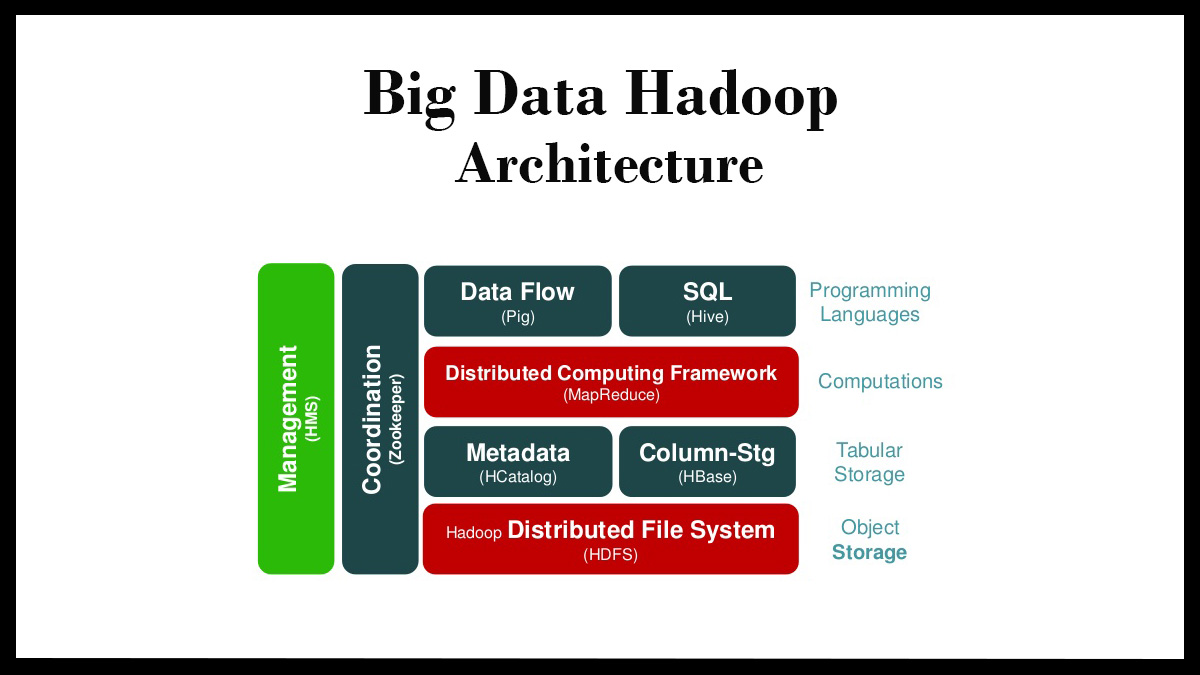
Importance of Hadoop in big data
Hadoop is essential especially in terms of big data . The importance of Hadoop is highlighted in the following points: Processing of huge chunks of data – With Hadoop, we can process and store huge amount of data mainly the data from social media and IoT(Internet of Things) applications. Computation power – The computation power of Hadoop is high as it can process big data pretty fast. Hadoop makes use of distributed models for processing of data. Fault tolerance – Hadoop provide protection against any form of malware as well as from hardware failure. If a node in the distributed model goes down, then other nodes continue to function. Copies of data are also stored. Flexibility – As much data as you require can be stored using Hadoop. There is no requirement of preprocessing the data. Low Cost – Hadoop is an open-source framework and free to use. It provides additional hardware to store the large quantities of data. Scalability – The system can be grown easily just by adding nodes in the system according to the requirements. Minimal administration is required.
Challenges of Hadoop
No doubt Hadoop is a very good platform for big data solution, still, there are certain challenges in this.
These challenges are:
- All problems cannot be solved – It is not suitable for iteration and interaction tasks. Instead, it is efficient for simple problems for which division into independent units can be made.
- Talent Gap – There is a lack of talented and skilled programmers in the field of MapReduce in big data especially at entry level.
- Security of data – Another challenge is the security of data. Kerberos authentication protocol has been developed to provide a solution to data security issues.
- Lack of tools – There is a lack of tools for data cleaning, management, and governance. Tools for data quality and standardization are also lacking.
Fields under Big Data
Big Data is a vast field and there are a number of topics and fields under it on which you can work for your thesis, dissertation as well as for research. Big Data is just an umbrella term for these fields.
Search Engine Data – It refers to the data stored in the search engines like Google, Bing and is retrieved from different databases. Social Media Data – It is a collection of data from social media platforms like Facebook, Twitter. Stock Exchange Data – It is a data from companies indulged into shares business in the stock market. Black box Data – Black Box is a component of airplanes, helicopters for voice recording of fight crew and for other metrics.
Big Data Technologies
Big Data technologies are required for more detailed analysis, accuracy and concrete decision making. It will lead to more efficiency, less cost, and less risk. For this, a powerful infrastructure is required to manage and process huge volumes of data.
The data can be analyzed with techniques like A/B Testing, Machine Learning, and Natural Language Processing.
The big data technologies include business intelligence, cloud computing, and databases.
The visualization of data can be done through the medium of charts and graphs.
Multi-dimensional big data can be handled through tensor-based computation. Tensor-based computation makes use of linear relations in the form of scalars and vectors. Other technologies that can be applied to big data are:
Massively Parallel Processing Search based applications Data Mining Distributed databases Cloud Computing
These technologies are provided by vendors like Amazon, Microsoft, IBM etc to manage the big data.
MapReduce Algorithm for Big Data
A large amount of data cannot be processed using traditional data processing approaches. This problem has been solved by Google using an algorithm known as the MapReduce algorithm. Using this algorithm, the task can be divided into small parts and these parts are assigned to distributed computers connected on the network. The data is then collected from individual computers to form a final dataset.
The MapReduce algorithm is used by Hadoop to run applications in which parallel processing of data is done on different nodes. Hadoop framework can develop applications that can run on clusters of computers to perform statistical analysis of a large amount of data.
The MapReduce algorithm consist of two tasks: Map Reduce
A set is of data is taken by Map which is converted into another set of data in which individual elements are broken into pairs known as tuples. Reduce takes the output of Map task as input. It combines data tuples into smaller tuples set.
The MapReduce algorithm is executed in three stages: Map Shuffle Reduce
In the map stage, the input data is processed and stored in the Hadoop file system(HDFS). After this a mapper performs the processing of data to create small chunks of data. Shuffle stage and Reduce stage occur in combination. The Reducer takes the input from the mapper for processing to create a new set of output which will later be stored in the HDFS. The Map and Reduce tasks are assigned to appropriate servers in the cluster by the Hadoop. The Hadoop framework manages all the details like issuing of tasks, verification, and copying. After completion, the data is collected at the Hadoop server. You can get thesis and dissertation guidance for the thesis in Big Data Hadoop from data analyst.
Applications of Big Data
Big Data find its application in various areas including retail, finance, digital media, healthcare, customer services etc.
Big Data is used within governmental services with efficiency in cost, productivity, and innovation. The common example of this is the Indian Elections of 2014 in which BJP tried this to win the elections. The data analysis, in this case, can be done by the collaboration between the local and the central government. Big Data was the major factor behind Barack Obama’s win in the 2012 election campaign.
Big Data is used in finance for market prediction. It is used for compliance and regulatory reporting, risk analysis, fraud detection, high-speed trading and for analytics. The data which is used for market prediction is known as alternate data.
Big Data is used in health care services for clinical data analysis, disease pattern analysis, medical devices and medicines supply, drug discovery and various other such analytics. Big Data analytics have helped in a major way in improving the healthcare systems. Using these certain technologies have been developed in healthcare systems like eHealth, mHealth, and wearable health gadgets.
Media uses Big Data for various mechanisms like ad targeting, forecasting, clickstream analytics, campaign management and loyalty programs. It is mainly focused on following three points:
Targeting consumers Capturing of data Data journalism
Big Data is a core of IoT(Internet of Things) . They both work together. Data can be extracted from IoT devices for mapping which helps in interconnectivity. This mapping can be used to target customers and for media efficiency by the media industry.
Information Technology
Big Data has helped employees working in Information Technology to work efficiently and for widespread distribution of Information Technology. Certain issues in Information Technology can also be resolved using Big Data. Big Data principles can be applied to machine learning and artificial intelligence for providing better solutions to the problems.
Advantages of Big Data
Big Data has certain advantages and benefits, particularly for big organizations.
- Time Management – Big data saves valuable time as rather than spending hours on managing the different amount of data, big data can be managed efficiently and at a faster pace.
- Accessibility – Big Data is easily accessible through authorization and data access rights and privileges.
- Trustworthy – Big Data is trustworthy in the sense that we can get valuable insights from the data.
- Relevant – The data is relevant whereas irrelevant data require filtering which can lead to complexity.
- Secure – The data is secured using data hosting and through various advanced technologies and techniques.
Challenges of Big Data
Although Big Data has come in a big way in improving the way we store data, there are certain challenges which need to be resolved.
- Data Storage and quality of Data – The data is growing at a fast pace as the number of companies and organizations are growing. Proper storage of this data has become a challenge. This data can be stored in data warehouses but this data is inconsistent. There are issues of errors, duplicacy, conflicts while storing this data in their native format. Moreover, this changes the quality of data.
- Lack of big data analysts – There is a huge demand for data scientists and analysts who can understand and analyze this data. But there are very few people who can work in this field considering the fact that huge amount of data is produced every day. Those who are there don’t have proper skills.
- Quality Analysis – Big companies and organizations use big for getting useful insights to make proper decisions for future plans. The data should also be accurate as inaccurate data can lead to wrong decisions that will affect the company business. Therefore quality analysis of the data should be there. For this testing is required which is a time-consuming process and also make use of expensive tools.
- Security and Privacy of Data – Security, and privacy are the biggest risks in big data. The tools that are used for analyzing, storing, managing use data from different sources. This makes data vulnerable to exposure. It increases security and privacy concerns.
Thus Big Data is providing a great help to companies and organizations to make better decisions. This will ultimately lead to more profit. The main thesis topics in Big Data and Hadoop include applications, architecture, Big Data in IoT, MapReduce, Big Data Maturity Model etc.
Latest Thesis and Research Topics in Big Data
There are a various thesis and research topics in big data for M.Tech and Ph.D. Following is the list of good topics for big data for masters thesis and research:
Big Data Virtualization
Internet of Things(IoT)
Big Data Maturity Model
Data Science
Data Federation
Big Data Analytics
SQL-on-Hadoop
Predictive Analytics
Big Data Virtualization is the process of creating virtual structures rather than actual for Big Data systems. It is very beneficial for big enterprises and organizations to use their data assets to achieve their goals and objectives. Virtualization tools are available to handle big data analytics.
Big Data and IoT work in coexistence with each other. IoT devices capture data which is extracted for connectivity of devices. IoT devices have sensors to sense data from its surroundings and can act according to its surrounding environment.
Big Data Maturity Models are used to measure the maturity of big data. These models help organizations to measure big data capabilities and also assist them to create a structure around that data. The main goal of these models is to guide organizations to set their development goals.
Data Science is more or less related to Data Mining in which valuable insights and information are extracted from data both structured and unstructured. Data Science employs techniques and methods from the fields of mathematics, statistics, and computer science for processing.
Data Federation is the process of collecting data from different databases without copying and without transferring the original data. Rather than whole information, data federation collects metadata which is the description of the structure of original data and keep them in a single database.
Sampling is a technique of statistics to find and locate patterns in Big Data. Sampling makes it possible for the data scientists to work efficiently with a manageable amount of data. Sampled data can be used for predictive analytics. Data can be represented accurately when a large sample of data is used.
It is the process of exploring large datasets for the sake of finding hidden patterns and underlying relations for valuable customer insights and other useful information. It finds its application in various areas like finance, customer services etc. It is a good choice for Ph.D. research in big data analytics.
Clustering is a technique to analyze big data. In clustering, a group of similar objects is grouped together according to their similarities and characteristics. In other words, this technique partitions the data into different sets. The partitioning can be hard partitioning and soft partitioning. There are various algorithms designed for big data and data mining. It is a good area for thesis and researh in big data.
SQL-on-Hadoop is a methodology for implementing SQL on Hadoop platform by combining together the SQL-style querying system to the new components of the Hadoop framework. There are various ways to execute SQL in Hadoop environment which include – connectors for translating the SQL into a MapReduce format, push down systems to execute SQL in Hadoop clusters, systems that distribute the SQL work between MapReduce – HDFS clusters and raw HDFS clusters. It is a very good topic for thesis and research in Big Data.
It is a technique of extracting information from the datasets that already exist in order to find out the patterns and estimate future trends. Predictive Analytics is the practical outcome of Big Data and Business Intelligence(BI). There are predictive analytics models which are used to get future insights. For this future insight, predictive analytics take into consideration both current and historical data. It is also an interesting topic for thesis and research in Big Data.
These were some of the good topics for big data for M.Tech and masters thesis and research work. For any help on thesis topics in Big Data, contact Techsparks . Call us on this number 91-9465330425 or email us at [email protected] for M.Tech and Ph.D. help in big data thesis topics.
Click on the following link to download the latest thesis and research topics in Big Data
Latest Thesis and Research Topics in Big Data(pdf)
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Quick Enquiry
Get a quote, share your details to get free.
Best Hadoop Projects
- [email protected]
- +91-97 91 62 64 69

Dissertation Topics on Big Data
Dissertation Topics on Big Data is the battle ground to combat against your discourage to get world’s praise worthy achievements. Our professionals are organized our institution by their hard work with the only main vision of serve students. We provide highly confidential and in-death research topics for students and research intellectuals from various department of information technology, computer science, electrical & electronic engineering, electrical & communication engineering. Our universal celebrated experts are maintaining our confidentiality what you expert from us. We never disclose your research and your identity to third person. If you felt about your dissertation, you can contact our organization by dint of our 24/12 experts service.
Dissertation Topics on Big Data grant our momentous research guidance for students and research intellectuals in each and every point of their research. On these days, we prepared thousands of big data projects by uptrend research concepts. In project development phase, we are using wide numerous data sets such as data matrix, graphs & networks (Social, web and molecular structures), ordered data (Temporal data, genetic sequence data, multimedia & image data, spatial data, video data, sequential data), and relational record. Prepare for the Dissertation topic is not going to be easy, but we will make it for you….. Don’t miss an opportunity to contacting us……….
How do you choose Dissertation topics on Big Data ? There are many dissertation topics and the possibilities while choosing topic is almost endless. This is why choosing dissertation topic is a difficult task for researchers. Here’s we provides some steps for selecting a topics for a dissertation, you can follow these steps and make a good dissertation topic.
Steps for Topic Selection:
- Generate new ideas or find a new ideas rather than pick just one
- Test your each idea through some reputed journal papers.
- Refine your ideas, once you have knowledge about your choices
The following are some Dissertation topics on Big Data which we currently working on:
- Learning Platform for Primary school pupils
- Data Centre Consolidation based on open source cloud platforms
- Benchmarking the clouds
- Building a secure distributed environment for information sharing across organizations
- Building a scalable application based on Hibernate/Spring/J2EE
- Building a Grid or Web Service(RESTful/SOAP)
- Mining the Big Data
For your every Dissertation Topics on Big Data , you need to concentrate on the following suggestions:
Data Origins
- Sensors, Internet, Machines, etc.
Data Collection
- Web log, Images/audio, RFID, Videos, Sensor Data, etc.
Data Storage
- Technologies, Support data storage, etc.
Data Processing
- Programming framework, Processing framework, etc.
Data Analytics
- Patterns in data, Decision making, Predictive Analytics, etc.
Data Consumers
- Humans, Business processes, Applications etc.
Today’s Top Dissertation Topics on Big Data :
- Opening Up Digital Archives to Identify Sensitive Content Over the Usage of Analytics
- Convolutional Networks for Aerial Images Based Large Scale Solar Panel Mapping
- Trolls and Control Terror Awareness Level Identification Using Scalable Paradigm in Social Networks
- Scaling Morphological Tagging Based Character to Fourteen Languages
- Dynamic Feature Selection and Generation for Music Recommendation on Heterogeneous Graph
- Research on Large Scale Water Monitoring Application in Spatial-Temporal Data for Identify Dynamic Changes based on Noisy Labels
- Evaluate Code Level Performance Tuning Impacts on Power Efficiency
- Efficient Data Access Schemes on HPC Clusters with Heterogeneous Storage for Spark and Hadoop
- Hierarchical and Hybrid Outlier Detection Strategy for Protect Large Scale Data
- Rule Based Diagnosis and Hierarchical Correlation Based Performance Analysis for Big Data Paradigms
- Analyze Data Partitioning and Data Replication Performance using BEOWULF Approach in Cloud
- Parallel Clustering Method for Spark Paradigm Based Non-Disjoint Large Scale Data Partitioning
- Rare Failure Events Prediction on Large Scale manufacturing and Complex Interaction Using Classification Trees
- Labeling Actors by Integrated Information within and Through Multiple Views in Multi-View Social Networks
- Dynamic Distributed Data Structure Using Spatial Data Mining Algorithms for Efficient Data Distribution between Cluster Nodes
Recent Posts
- Hadoop related projects
- Hadoop based projects
- Hadoop Research Projects
- Sample Hadoop Projects
- big data hadoop projects
- hadoop big data projects
- hadoop open source projects
- projects on big data hadoop
- Projects Based on Hadoop
- Projects Using Hadoop
- Projects in Hadoop
- open source project related to hadoop
- big data based projects
- big data projects list
- interesting big data projects
- projects on big data
- big data projects for beginners
- big data open source projects
- big data project topics
- open source big data projects
- simple big data projects
- projects based on big data
- big data real time projects
- big data research projects
- big data analysis open source projects
- big data projects for final year
- big data mini projects
- ieee projects on big data
- ieee big data projects
- cool big data projects
- big data student projects
- project ideas on big data
- big data ieee projects
- projects in big data
- big data related projects
- big data project titles
- project topics on big data
- apache projects for big data
- projects related to big data
- dissertation topics on big data
- phd thesis big data
- phd thesis on big data analytics
- thesis on big data analytics
- projects in big data analytics
- Projects on Hadoop
- data analytics projects
Achievements – Hadoop Solutions

YouTube Channel

Customer Review

Other Pages
Quick links.
- Hadoop Projects
- Big Data Projects
- Hadoop Thesis
- MapReduce Project Ideas
- Big Data Analytics Projects
Support Through
© 2015 HADOOP SOLUTIONS|Theme Developed By Hadoop Solutions | Dissertation project topics
Opinion: Americans might finally get a real privacy law to fight Big Tech intrusions

- Show more sharing options
- Copy Link URL Copied!
This month, Sen. Maria Cantwell (D-Wash.) and Rep. Cathy McMorris Rodgers (R-Wash.) unveiled a rare government feat: a bipartisan bill that has lawmakers feeling “optimistic” and “ fired up .”
It’s the American Privacy Rights Act (APRA), and it’s long overdue. The U.S. lags far behind the rest of the world on privacy legislation; 137 of the world’s 194 countries have national privacy laws, according to the United Nations. We’re the G-20 outlier without one . This isn’t the kind of “exceptionalism” Americans should strive for.

Opinion: The misuse of personal data is everywhere. Here’s one measure that fights back
California’s laws are too unwieldy to provide real online privacy protection. The Delete Act would create a one-step mechanism for consumers to get every data broker to delete their personal information.
Sept. 6, 2023
The proposal, which aims to “ make privacy a consumer right ” and “give consumers the ability to enforce that right,” comes at a pivotal moment. On April 20, President Biden signed a bill to reauthorize the Foreign Intelligence Surveillance Act. While this law is a tool for safeguarding national security against foreign targets, it also allows collection of the web and cellphone data of hundreds of thousands of Americans and has a history of abuse by intelligence agencies. Meanwhile, the new law forcing a sale or ban of TikTok , meant to prevent foreign access to Americans’ data, provides only narrow protections.
Congress is under enormous pressure to deal with the rise of AI, combat surveillance capitalism and reduce the serious harms tech companies inflict upon kids and teens . There have been other federal privacy proposals, but they have failed in our gridlocked Congress. Led by the chairs of the House and Senate Commerce committees, APRA is the first to gain significant bipartisan and bicameral support .
The immediate need for this legislation is clear. Tech companies aren’t the only culprits guilty of misusing our data. In March, General Motors was caught in a scandal when it was found sharing data on its customers’ driving behavior with insurance companies via data brokers — those often massive, multibillion-dollar companies that exist to buy, sell and resell our data.

Opinion: You don’t need to own an iPhone for the government lawsuit against Apple to benefit you
The Justice Department is arguing that Apple has degraded the iPhone user experience and the products of competitors. A victory would give consumers more choice in our digital lives.
April 22, 2024
This speaks to part of APRA’s appeal : It’s remarkably broad. It would encompass the private sector, not-for-profits and common carriers, including tech and other companies and medium or large organizations that handle our data. And it proposes extra restrictions on data brokers.
To minimize data sharing, the legislation would prevent companies and organizations from collecting data that is not “necessary” or “proportionate” to the purpose for which the data is collected. In a victory for transparency, entities would be required to disclose the data they have on you and explicitly allow you to edit or delete it. In addition, it would require companies to allow consumers to opt out of targeted advertising and data collection by brokers. And finally, this legislation would allow you to sue companies and seek financial damages for violations of your privacy rights.
The bill faces some significant criticisms, including from leading privacy advocates and organizations. A post from the Electronic Frontier Foundation took issue with the bill “preempting existing state laws and preventing states from creating stronger protections in the future,” warning that this condition “would freeze consumer data privacy protections in place.” Caitriona Fitzgerald, deputy director at the Electronic Privacy Information Center, cautioned that any preemptive legislation should be stronger than existing state laws — which APRA currently is not, she suggested.

California lawmakers pass bill to make it easier to delete online personal data
California lawmakers on Thursday passed a bill known as the Delete Act that would allow consumers, with a single request, to have every data broker delete their personal information.
Sept. 14, 2023
The Electronic Frontier Foundation post argued that, for example, the bill should “limit sharing with the government and expand the definition of sensitive data.” And the ranking member of the House Energy and Commerce Committee, Rep. Frank Pallone Jr. (D-N.J.), said the bill “could be stronger in certain areas, such as children’s privacy.”
These criticisms are valid but not enough so to derail the proposal. Consider that California has among the strongest state privacy laws , yet tech giants such as Meta and Google , which make their homes here, are still accused of some of the most egregious privacy violations. A powerful and universal federal law is required to rein them in. It would also be more effective than the status quo of a byzantine patchwork of state laws.
And APRA can be strengthened over time. That happened with the Children’s Online Privacy Protection Act , passed in 1998 to protect children under age 13. In 2013, the law was broadened and updated by the Federal Trade Commission to reflect evolving technology such as mobile devices. It also expanded the definition of “personal information” to include geolocation data, photos, videos, audio of children and more. Once passed, APRA could similarly serve as a foundation for future improvements.
Eventually it could be strengthened with an important guardrail like one built into the U.K.’s Online Safety Act . Depending on the severity of the violation, it imposes jail time for executives and fines of up to $22 million or 10% of a company’s gross revenue, whichever is greater. These harsh penalties can help prevent the trend of tech giants routinely flouting privacy laws by simply paying fines as costs of doing business.
The bill‘s review by committees in both chambers of Congress may bolster it further. Our government should not waste this watershed moment to establish a bedrock of privacy rights for all Americans.
Mark Weinstein is a tech entrepreneur, privacy expert and the author of the forthcoming book “ Restoring Our Sanity Online. ”
More to Read

Questions swirl over the future of TikTok. Who could own it? How will the platform operate?
April 24, 2024

Legislation banning TikTok is coming this week. How will it affect the music industry?

Editorial: Social media companies refuse to safeguard kids. It’s up to lawmakers now
A cure for the common opinion
Get thought-provoking perspectives with our weekly newsletter.
You may occasionally receive promotional content from the Los Angeles Times.
More From the Los Angeles Times

Abcarian: Don’t denigrate pro-Palestinian campus protests by claiming the Vietnam War protests backfired
May 3, 2024

Granderson: The chaos in Congress is more dangerous than the protests on campuses

Opinion: Is Biden a YIMBY? He certainly has good reason to embrace a pro-housing agenda

Opinion: What a quail taught me about grief by joining a flock of turkeys
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Preventing the Next Big Cyberattack on U.S. Health Care
- Erik Decker,
- John Glaser,
- Janet Guptill

Five actions that can help avoid a repeat of the Change Healthcare debacle.
The cyberattack on Change Healthcare that devastated the U.S. health care sector made painfully clear that much more needs to be done to address vulnerabilities that exist throughout the ecosystem. This article offers five actions that can go a long way to improving cybersecurity throughout the sector and make it much more resilient.
This past February, a ransomware attack on a company called Change Healthcare brought medical billing in the United States to a standstill and propelled hundreds of financially strapped health systems and medical practices to the brink of bankruptcy. The breach paralyzed the cash flow of many of the organizations that collectively account for a fifth of the U.S. economy, potentially compromised as many as 85 million patient records, and cost billions of dollars. Recovery is still in progress as we write, and it may be months or years before the final toll is known.
- Erik Decker is a vice president and the chief information security officer at Intermountain Health. He chairs the Health Sector Coordinating Council’s Cybersecurity Working Group, an industry-led council of more than 400 healthcare organizations that advises the government and health sector on how to protect against and recover from cyberthreats. He also co-leads the 405(d) Task Group, a collaborative effort between the Health Sector Coordinating Council and the U.S. government to align the health care sector’s security practices.
- John Glaser is an executive in residence at Harvard Medical School. He previously served as the CIO of Partners Healthcare (now Mass General Brigham), a senior vice president at Cerner, and the CEO of Siemens Health Services. He is co-chair of the HL7 Advisory Council and a board member of the National Committee for Quality Assurance.
- Janet Guptill is president and CEO of the Scottsdale Institute, a not-for-profit organization dedicated to helping its more than 60 large, integrated health systems leverage information and technology to create effective, affordable, and equitable health care centered on whole person care.
Partner Center
We've detected unusual activity from your computer network
To continue, please click the box below to let us know you're not a robot.
Why did this happen?
Please make sure your browser supports JavaScript and cookies and that you are not blocking them from loading. For more information you can review our Terms of Service and Cookie Policy .
For inquiries related to this message please contact our support team and provide the reference ID below.
- Share full article
Advertisement
Supported by
In Race to Build A.I., Tech Plans a Big Plumbing Upgrade
The spending that the industry’s giants expect artificial intelligence to require is starting to come into focus — and it is jarringly large.

By Karen Weise
Karen Weise covers technology from Seattle.
If 2023 was the tech industry’s year of the A.I. chatbot, 2024 is turning out to be the year of A.I. plumbing. It may not sound as exciting, but tens of billions of dollars are quickly being spent on behind-the-scenes technology for the industry’s A.I. boom.
Companies from Amazon to Meta are revamping their data centers to support artificial intelligence. They are investing in huge new facilities, while even places like Saudi Arabia are racing to build supercomputers to handle A.I. Nearly everyone with a foot in tech or giant piles of money, it seems, is jumping into a spending frenzy that some believe could last for years.
Microsoft, Meta, and Google’s parent company, Alphabet, disclosed this week that they had spent more than $32 billion combined on data centers and other capital expenses in just the first three months of the year. The companies all said in calls with investors that they had no plans to slow down their A.I. spending.
In the clearest sign of how A.I. has become a story about building a massive technology infrastructure, Meta said on Wednesday that it needed to spend billions more on the chips and data centers for A.I. than it had previously signaled.
“I think it makes sense to go for it, and we’re going to,” Mark Zuckerberg, Meta’s chief executive, said in a call with investors.
The eye-popping spending reflects an old parable in Silicon Valley: The people who made the biggest fortunes in California’s gold rush weren’t the miners — they were the people selling the shovels. No doubt Nvidia, whose chip sales have more than tripled over the last year, is the most obvious A.I. winner.
The money being thrown at technology to support artificial intelligence is also a reminder of spending patterns of the dot-com boom of the 1990s. For all of the excitement around web browsers and newfangled e-commerce websites, the companies making the real money were software giants like Microsoft and Oracle, the chipmaker Intel, and Cisco Systems, which made the gear that connected those new computer networks together.
But cloud computing has added a new wrinkle: Since most start-ups and even big companies from other industries contract with cloud computing providers to host their networks, the tech industry’s biggest companies are spending big now in hopes of luring customers.
Google’s capital expenditures — largely the money that goes into building and outfitting data centers — almost doubled in the first quarter, the company said. Microsoft’s were up 22 percent . Amazon, which will report earnings on Tuesday, is expected to add to that growth.
Meta’s investors were unhappy with Mr. Zuckerberg, sending his company’s share price down more than 16 percent after the call. But Mr. Zuckerberg, who just a few years ago was pilloried by shareholders for a planned spending spree on augmented and virtual reality, was unapologetic about the money that his company is throwing at A.I. He urged patience, potentially for years.
“Our optimism and ambitions have just grown quite a bit,” he said.
Investors had no problem stomaching Microsoft’s spending. Microsoft is the only major tech company to report financial details of its generative A.I. business, which it said had contributed to more than a fifth of the growth of its cloud computing business. That amounted to $1 billion in three months, analysts estimated.
Microsoft said its generative A.I. business could have been even bigger — if the company had enough data center supply to meet the demand, underscoring the need to keep on building.
The A.I. investments are creating a halo for Microsoft’s core cloud computing offering, Azure, helping it draw new customers. “Azure has become a port of call for pretty much anybody who is doing any A.I. project,” Satya Nadella, Microsoft’s chief executive, said on Thursday.
(The New York Times sued Microsoft and its partner, OpenAI, in December, claiming copyright infringement of news content related to their A.I. systems.)
Google said sales from its cloud division were up 28 percent, including “an increasing contribution from A.I.”
In a letter to shareholders this month, Andy Jassy, Amazon’s chief executive, said that much attention had been paid to A.I. applications, like ChatGPT, but that the opportunity for more technical efforts, around infrastructure and data, was “gigantic.”
For the computing infrastructure, “the key is the chip inside it,” he said, emphasizing that bringing down costs and wringing more performance out of the chips is key to Amazon’s effort to develop its own A.I. chips .
Infrastructure demands generally fall into two buckets: First, there is building the largest, cutting-edge models, which some A.I. developers say could soon top $1 billion for each new round. Chief executives said that being able to work on developing cutting-edge systems, either directly or with partners, was essential for remaining at the forefront of A.I.
And then there is what’s called inferencing, or querying the models to actually use them. This can involve customers tapping into the systems, like an insurer using generative A.I. to summarize a customer complaint, or the companies themselves putting A.I. directly into their own products, as Meta recently did by embedding a chatbot assistant in Facebook and Instagram. That’s also expensive.
Data centers take time to build and outfit. Chips face supply shortages and costly fabrication. With such long-term bets, Susan Li, Meta’s finance chief, said the company was building with “fungibility.” It wants wiggle room to change how it uses the infrastructure, if the future turns out to be not exactly what it expects.
Karen Weise writes about technology and is based in Seattle. Her coverage focuses on Amazon and Microsoft, two of the most powerful companies in America. More about Karen Weise
- Work & Careers
- Life & Arts
Become an FT subscriber
Try unlimited access Only $1 for 4 weeks
Then $75 per month. Complete digital access to quality FT journalism on any device. Cancel anytime during your trial.
- Global news & analysis
- Expert opinion
- Special features
- FirstFT newsletter
- Videos & Podcasts
- Android & iOS app
- FT Edit app
- 10 gift articles per month
Explore more offers.
Standard digital.
- FT Digital Edition
Premium Digital
Print + premium digital, weekend print + standard digital, weekend print + premium digital.
Today's FT newspaper for easy reading on any device. This does not include ft.com or FT App access.
- Global news & analysis
- Exclusive FT analysis
- FT App on Android & iOS
- FirstFT: the day's biggest stories
- 20+ curated newsletters
- Follow topics & set alerts with myFT
- FT Videos & Podcasts
- 20 monthly gift articles to share
- Lex: FT's flagship investment column
- 15+ Premium newsletters by leading experts
- FT Digital Edition: our digitised print edition
- Weekday Print Edition
- Videos & Podcasts
- Premium newsletters
- 10 additional gift articles per month
- FT Weekend Print delivery
- Everything in Standard Digital
- Everything in Premium Digital
Essential digital access to quality FT journalism on any device. Pay a year upfront and save 20%.
- 10 monthly gift articles to share
- Everything in Print
Complete digital access to quality FT journalism with expert analysis from industry leaders. Pay a year upfront and save 20%.
Terms & Conditions apply
Explore our full range of subscriptions.
Why the ft.
See why over a million readers pay to read the Financial Times.
International Edition
- Mobile Site
- Staff Directory
- Advertise with Ars
Filter by topic
- Biz & IT
- Gaming & Culture
Front page layout
FCC fines —
Fcc fines big three carriers $196m for selling users’ real-time location data, fcc finalizes $196m penalties for location-data sales revealed in 2018..
Jon Brodkin - Apr 29, 2024 7:51 pm UTC

The Federal Communications Commission today said it fined T-Mobile, AT&T, and Verizon $196 million "for illegally sharing access to customers' location information without consent and without taking reasonable measures to protect that information against unauthorized disclosure."
The fines relate to sharing of real-time location data that was revealed in 2018 . The FCC proposed the fines in 2020, when the commission had a Republican majority, and finalized them today.
All three major carriers vowed to appeal the fines after they were announced today. The three carriers also said they discontinued the data-sharing programs that the fines relate to.
The fines are $80.1 million for T-Mobile, $57.3 million for AT&T, and $46.9 million for Verizon. T-Mobile is also on the hook for a $12.2 million fine issued to Sprint, which was bought by T-Mobile shortly after the penalties were proposed over four years ago.
Today, the FCC summarized its findings as follows:
The FCC Enforcement Bureau investigations of the four carriers found that each carrier sold access to its customers' location information to "aggregators," who then resold access to such information to third-party location-based service providers. In doing so, each carrier attempted to offload its obligations to obtain customer consent onto downstream recipients of location information, which in many instances meant that no valid customer consent was obtained. This initial failure was compounded when, after becoming aware that their safeguards were ineffective, the carriers continued to sell access to location information without taking reasonable measures to protect it from unauthorized access.
“Shady actors” got hold of data
The problem first came to light with reports of customer location data "being disclosed by the largest American wireless carriers without customer consent or other legal authorization to a Missouri Sheriff through a 'location-finding service' operated by Securus, a provider of communications services to correctional facilities, to track the location of numerous individuals," the FCC said.
Chairwoman Jessica Rosenworcel said that news reports in 2018 "revealed that the largest wireless carriers in the country were selling our real-time location information to data aggregators, allowing this highly sensitive data to wind up in the hands of bail-bond companies, bounty hunters, and other shady actors. This ugly practice violates the law—specifically Section 222 of the Communications Act, which protects the privacy of consumer data."
For a time after the 2018 reports, "all four carriers continued to operate their programs without putting in place reasonable safeguards to ensure that the dozens of location-based service providers with access to their customers' location information were actually obtaining customer consent," the FCC said.
The three carriers are ready to challenge the fines in court. "This industry-wide third-party aggregator location-based services program was discontinued more than five years ago after we took steps to ensure that critical services like roadside assistance, fraud protection and emergency response would not be disrupted," T-Mobile said in a statement provided to Ars. "We take our responsibility to keep customer data secure very seriously and have always supported the FCC's commitment to protecting consumers, but this decision is wrong, and the fine is excessive. We intend to challenge it."
reader comments
Channel ars technica.
COMMENTS
The Evolution of Big Data and Its Business Applications. Doctor of Philosophy (Information Science), May 2018, 113 pp., 12 tables, 10 figures, references, 203 titles. The arrival of the Big Data era has become a major topic of discussion in many sectors because of the premises of big data utilizations and its impact on decisionmaking. It is an -
The value of big data is understandable when the data is used analytically to create or enable new services and products. Big data analytics refers to using computational method to gain value from the data. To process, store, manage and analyze big data; many tools and technologies are being developed by individuals and companies.
successfully. Adopting big data analytics implementation strategies may benefit leaders to successfully achieve business goals to improve organizational performance while reducing operating costs. Background of the Problem . Implementing big data analytics has the potential to improve a company's competitive advantage, growth, and performance.
MASTER THESIS Big Data and Business Intelligence: a data-driven strategy for e-commerce organizations in the hotel industry Date 03-09-2015 Personal information Author Mike Padberg E-mail [email protected] Study program Master in Business Administration Business Information Management ...
This dissertation explores three topics related to random forests: tree aggregation, variable importance, and robustness. 10. Climate Data Computing: Optimal Interpolation, Averaging, Visualization and Delivery. This dissertation solves two important problems in the modern analysis of big climate data.
unstructured digital health data referred to as. big data, has outpaced the capacity to analyze and derive actionable information (Prosperi et al., 2018). BDA, which is the integration and processing of heterogeneous digital data with specialized tools to discover new relationships and discover actionable insights (Ristevski & Chen, 2018), has the
2014 — Volume 1. Read the latest articles of Big Data Research at ScienceDirect.com, Elsevier's leading platform of peer-reviewed scholarly literature.
Urban Accessibility Measurement and Visualization—A Big Data Approach (Committee: Drs. Diansheng Guo, Zhenlong Li, Michael E. Hodgson) Undergraduate Theses (Honors and Graduate with Distinction) Finn Hagerty (2021), Tracking Population Movement using Geotagged Tweets to and from New York City and Los Angeles during the COVID-19 Pandemic ...
Big data analytics in computational biology and bioinformatics refers to an array of operations including biological pattern discovery, classification, prediction, inference, clustering as well as data mining in the cloud, among others. This dissertation addresses big data analytics by investigating two important operations, namely pattern discovery and network inference.
This machine learning dissertation analyzes data to build a quantitative understanding of the world. Linear algebra is the foundation of algorithms, dating back one hundred years, for extracting structure from data. ... In the era of big data, uncovering useful information and hidden patterns in the data is prevalent in different fields ...
The term big data refers to the technology which processes a huge amount of data in various formats within a fraction of seconds.Big data handles the research domains by means of managing their data loads. Big data dissertation helps to convey the perceptions on the proposed research problems. It is also known as the new generation technology which could compatible with high-speed data ...
by Kevin Byron. Big data analytics in computational biology and bioinformatics refers to an array of operations including biological pattern discovery, classification, prediction, inference, clustering as well as data mining in the cloud, among others. This dissertation addresses big data analytics by investigating two important operations ...
Consult the top 50 dissertations / theses for your research on the topic 'Big data frameworks.'. Next to every source in the list of references, there is an 'Add to bibliography' button. Press on it, and we will generate automatically the bibliographic reference to the chosen work in the citation style you need: APA, MLA, Harvard, Chicago ...
Data mining is concerned with knowledge discovery and finding patterns in. datasets through a process of applying the model to the data [13]. The model, the heart of. the data mining proce ss, is ...
Knapton III, Kenneth Stanley, "Exploring Mid-Market Strategies for Big Data Governance" (2020). Walden Dissertations and Doctoral Studies. 9161. Many data scientists are struggling to adopt effective data governance practices as they transition from traditional data analysis to big data analytics. Data governance of big data requires new ...
These 15 topics will help you to dive into interesting research. You may even build on research done by other scholars. Evaluate the data mining process. The influence of the various dimension reduction methods and techniques. The best data classification methods. The simple linear regression modeling methods.
Big data evolution and the Internet of Things (IoT) have taken precedence in many organizations. with the intent o f spearheading decision making and enhancing producti v ity. A study conducted ...
Below is a selection of dissertations from the Doctor of Philosophy in Computational and Data Sciences program in Schmid College that have been included in Chapman University Digital Commons. Additional dissertations from years prior to 2019 are available through the Leatherby Libraries' print collection or in Proquest's Dissertations and ...
The time required to write a master's level full dissertation varies, but it typically takes 6-12 months, depending on research complexity and individual pace. This is a sample Masters' level full dissertation in the area of big data, developed by our experts and demonstrates the quality of our work.
Abstract : The phenomenon of digitalization has led to the emergence of a new term—big data. Big data refers to the vast volumes of digital data characterized by its volume, velocity, variety, veracity, and value. READ MORE. 4. Big Data Analytics for Fault Detection and its Application in Maintenance.
The main thesis topics in Big Data and Hadoop include applications, architecture, Big Data in IoT, MapReduce, Big Data Maturity Model etc. Latest Thesis and Research Topics in Big Data. There are a various thesis and research topics in big data for M.Tech and Ph.D. Following is the list of good topics for big data for masters thesis and research:
The following are some Dissertation topics on Big Data which we currently working on: Learning Platform for Primary school pupils. Data Centre Consolidation based on open source cloud platforms. Benchmarking the clouds. Building a secure distributed environment for information sharing across organizations.
A third of Americans may have had their personal data swept up in a February ransomware attack on a UnitedHealth Group subsidiary that disrupted pharmacies across the US, UnitedHealth CEO Andrew ...
Opinion: The misuse of personal data is everywhere. Here's one measure that fights back. Sept. 6, 2023. The proposal, which aims to " make privacy a consumer right " and "give consumers ...
In Virginia's data-center alley, rising power demand means more fossil fuels. LOUDOUN COUNTY, Va.—. The cutting edge of technology is driving the power grid back to the 19th century. An ...
The cyberattack on Change Healthcare that devastated the U.S. health care sector made painfully clear that much more needs to be done to address vulnerabilities that exist throughout the ecosystem.
April 29, 2024 at 3:00 PM PDT. The US push to ban TikTok marks a new phase in its approach to data security that could eventually impact everything from electric vehicles to health care, reshaping ...
April 27, 2024. If 2023 was the tech industry's year of the A.I. chatbot, 2024 is turning out to be the year of A.I. plumbing. It may not sound as exciting, but tens of billions of dollars are ...
SEC shuts down Trump Media auditor over 'massive fraud' Private equity firms step up plans to edge banks out of low-risk lending; US stocks rally as cooling labour market boosts rate cut hopes
The three carriers also said they discontinued the data-sharing programs that the fines relate to. The fines are $80.1 million for T-Mobile, $57.3 million for AT&T, and $46.9 million for Verizon.