Twitter’s new API platform now opened to academic researchers

Twitter today is rolling out a new product track on its API platform, as part of its ongoing efforts to rebuild the Twitter API from the ground up. The track, which aims to serve the needs of the academic research community’s efforts, offers broader access to the Twitter archive and fewer restrictions on tweet retrievals, so researchers can access the entire history of the public conversation on Twitter’s platform.
In addition to gaining access to all the Twitter API v2 endpoints released to date and elevated access, researchers will gain access to more precise filtering capabilities.
Specifically, they’ll be able to access the full-archive search endpoint, which offers access to everything being said on Twitter. They can narrow searches for these historical tweets using start time and end time parameters.
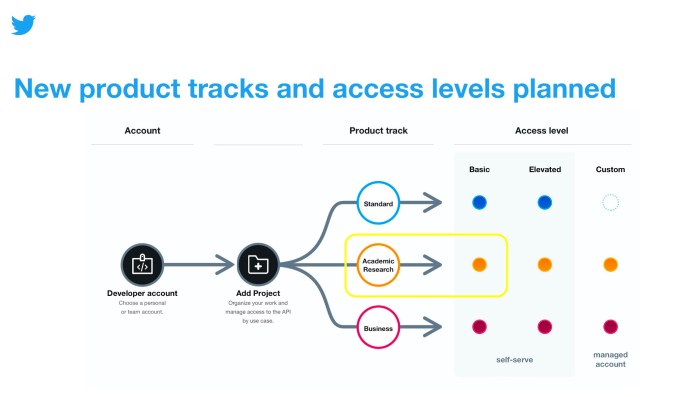
Researchers will also gain a significantly higher monthly cap on the number of tweets they can pull using the Twitter API v2. While on the Basic level of API access, this cap is set to 500,000. The Basic level of access on the Academic Research track is an initial monthly cap of up to 10 million tweets. This applies to the Recent Search, Filtered Stream, Full-archive search, and user tweet and mentions timelines endpoints, Twitter says.
The Academic Research track will gain access to certain operators that aren’t otherwise available, too, with the goal of helping them pull more precise user data. Today, these include: $ (aka cashtag), bio, bio_name, bio_location, place, place_country, point_radius, bounding_box, -is:nullcast, has:cashtags and has:geo.
Researchers can also add 1,000 concurrent rules when using the filter stream endpoint, instead of the limit of 25 available in the Standard track. Queries in the recent search endpoint can be 1,024 characters long, compared with 512 characters in the Standard track.
Because of the elevated levels of access, those who want to gain access to the Academic Research product track have to first submit an application .
All applicants have to either be a master’s student, doctoral candidate, post-doc, faculty or research-focused employee at an academic institution or university. They will also need to have a clearly defined research objective and must be able to detail their specific plans for how they intend to use, analyze and share Twitter data from their research.
Plus, the data used from the Academic Research product track can’t be used for any commercial purposes, Twitter notes.
Academic researchers have been taking advantage of the Twitter API since its first introduction in 2006 and have used the data to study a variety of topics, Twitter says, like state-backed efforts to disrupt the public conversation , floods and climate change , attitudes and perceptions about COVID-19 and efforts to promote healthy conversation online .
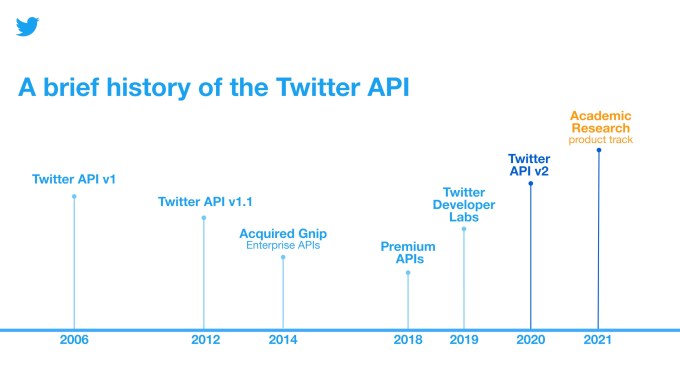
However, the earlier version of the Twitter API didn’t make it easy for researchers to gain access to Twitter data — something the company wanted to correct with API v2.
Twitter to date has catered to the research community in other ways, with additions like a website dedicated to academic research, updates to its developer policy to make it easier to reproduce and validate others’ research, and even special endpoints, like the COVID-19 stream endpoint released in April 2020. But it hasn’t fully thought through, until the API v2, how it could build tools that would actually aid researchers in doing their work, instead of the researchers having to figure out ways to work around Twitter’s limitations.
The Academic Research product track was tested in private beta starting in Oct. 2020, and now this is being opened more broadly, where it will be made freely available.
Twitter says it’s planning to add higher levels of access across all its product tracks in the future, including this one, in time. The later levels will help researchers who need even more data than what’s being offered with today’s launch. Twitter also noted it’s looking into adding flexible access as well, which would help account for times when developers were consuming more or less data throughout the year.
Twitter acquires newsletter platform Revue

More TechCrunch
Get the industry’s biggest tech news, techcrunch daily news.
Every weekday and Sunday, you can get the best of TechCrunch’s coverage.
Startups Weekly
Startups are the core of TechCrunch, so get our best coverage delivered weekly.
TechCrunch Fintech
The latest Fintech news and analysis, delivered every Sunday.
TechCrunch Mobility
TechCrunch Mobility is your destination for transportation news and insight.
Temu accused of breaching EU’s DSA in bundle of consumer complaints
Consumer protection groups around the European Union have filed coordinated complaints against Temu, accusing the Chinese-owned ultra low-cost e-commerce platform of a raft of breaches related to the bloc’s Digital…

Google I/O 2024: Here’s everything Google just announced
Here are quick hits of the biggest news from the keynote as they are announced.

Senate study proposes ‘at least’ $32B yearly for AI programs
The AI industry moves faster than the rest of the technology sector, which means it outpaces the federal government by several orders of magnitude.

FBI seizes hacking forum BreachForums — again
The FBI along with a coalition of international law enforcement agencies seized the notorious cybercrime forum BreachForums on Wednesday. For years, BreachForums has been a popular English-language forum for hackers…

Netflix to take on Google and Amazon by building its own ad server
The announcement signifies a significant shake-up in the streaming giant’s advertising approach.

Matt Garman taking over as CEO with AWS at crossroads
It’s tough to say that a $100 billion business finds itself at a critical juncture, but that’s the case with Amazon Web Services, the cloud arm of Amazon, and the…

Google still hasn’t fixed Gemini’s biased image generator
Back in February, Google paused its AI-powered chatbot Gemini’s ability to generate images of people after users complained of historical inaccuracies. Told to depict “a Roman legion,” for example, Gemini would show…

Google’s call-scanning AI could dial up censorship by default, privacy experts warn
A feature Google demoed at its I/O confab yesterday, using its generative AI technology to scan voice calls in real time for conversational patterns associated with financial scams, has sent…
The top AI announcements from Google I/O
Google’s going all in on AI — and it wants you to know it. During the company’s keynote at its I/O developer conference on Tuesday, Google mentioned “AI” more than…

Uber has a new way to solve the concert traffic problem
Uber is taking a shuttle product it developed for commuters in India and Egypt and converting it for an American audience. The ride-hail and delivery giant announced Wednesday at its…

Google takes aim at Android malware with an AI-powered live threat detection service
Google is preparing to launch a new system to help address the problem of malware on Android. Its new live threat detection service leverages Google Play Protect’s on-device AI to…
Google Maps is getting geospatial AR content later this year
Users will be able to access the AR content by first searching for a location in Google Maps.

Quilt heat pump sports sleek design from veterans of Apple, Tesla and Nest
The heat pump startup unveiled its first products and revealed details about performance, pricing and availability.

Google’s new Private Space feature is like Incognito Mode for Android
The space is available from the launcher and can be locked as a second layer of authentication.

Google TV to launch AI-generated movie descriptions
Gemini, the company’s family of generative AI models, will enhance the smart TV operating system so it can generate descriptions for movies and TV shows.

Android’s new Theft Detection Lock helps deter smartphone snatch and grabs
When triggered, the AI-powered feature will automatically lock the device down.

Google adds live threat detection and screen-sharing protection to Android
The company said it is increasing the on-device capability of its Google Play Protect system to detect fraudulent apps trying to breach sensitive permissions.

Wear OS 5 hits developer preview, offering better battery life
This latest release, one of many announcements from the Google I/O 2024 developer conference, focuses on improved battery life and other performance improvements, like more efficient workout tracking.

Dietitian startup Fay has been booming from Ozempic patients and emerges from stealth with $25M from General Catalyst, Forerunner
For years, Sammy Faycurry has been hearing from his registered dietitian (RD) mom and sister about how poorly many Americans eat and their struggles with delivering nutritional counseling. Although nearly…

Apple announces new accessibility features for iPhone and iPad users
Apple is bringing new accessibility features to iPads and iPhones, designed to cater to a diverse range of user needs.

Startup Blueprint: TC Disrupt 2024 Builders Stage agenda sneak peek!
TechCrunch Disrupt, our flagship startup event held annually in San Francisco, is back on October 28-30 — and you can expect a bustling crowd of thousands of startup enthusiasts. Exciting…

Anthropic hires Instagram co-founder as head of product
Mike Krieger, one of the co-founders of Instagram and, more recently, the co-founder of personalized news app Artifact (which TechCrunch corporate parent Yahoo recently acquired), is joining Anthropic as the…

Venture orgs form alliance to standardize data collection
Seven orgs so far have signed on to standardize the way data is collected and shared.

Alkira connects with $100M for a solution that connects your clouds
Alkira has raised $100M for its “network infrastructure as a service,” which lets users virtualize and orchestrate hybrid cloud assets, and manage them.

Orange Charger thinks a $750 outlet will solve EV charging for apartment dwellers
Charging has long been the Achilles’ heel of electric vehicles. One startup thinks it has a better way for apartment dwelling EV drivers to charge overnight.

Embedded accounting startup Layer secures $2.3M toward goal of replacing QuickBooks
So did investors laugh them out of the room when they explained how they wanted to replace Quickbooks? Kind of.

Weka raises $140M as the AI boom bolsters data platforms
While an increasing number of companies are investing in AI, many are struggling to get AI-powered projects into production — much less delivering meaningful ROI. The challenges are many. But…

Meet PayHOA, a profitable and once-bootstrapped SaaS startup that just landed a $27.5M Series A
PayHOA, a previously bootstrapped Kentucky-based startup that offers software for self-managed homeowner associations (HOAs), is an example of how real-world problems can translate into opportunity. It just raised a $27.5…

Restaurant365 orders in $175M at $1B+ valuation to supersize its food service software stack
Restaurant365, which offers a restaurant management suite, has raised a hot $175M from ICONIQ Growth, KKR and L Catterton.

Portuguese VC firm Shilling launches €50M opportunity fund to back growth-stage startups
Venture firm Shilling has launched a €50M fund to support growth-stage startups in its own portfolio and to invest in startups everywhere else.

- Twitter - X /
Twitter just closed the book on academic research
Twitter was once an indispensable resource for academic research. that’s changed under elon musk..
By Justine Calma , a senior science reporter covering climate change, clean energy, and environmental justice with more than a decade of experience. She is also the host of Hell or High Water: When Disaster Hits Home, a podcast from Vox Media and Audible Originals.
Share this story
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24691402/1258281169.jpg "academic research api twitter")
Twitter was once a mainstay of academic research — a way to take the pulse of the internet. But as new owner Elon Musk has attempted to monetize the service, researchers are struggling to replace a once-crucial tool. Unless Twitter makes another about-face soon, it could close the chapter on an entire era of research.
“Research using social media data, it was mostly Twitter-ology,” says Gordon Pennycook, an associate professor of behavioral science at the University of Regina. “It was the primary source that people were using,”
“It was mostly Twitter-ology.”
Until Musk’s takeover, Twitter’s API — which allows third-party developers to gather data — was considered one of the best on the internet. It enabled studies into everything from how people respond to weather disasters to how to stop misinformation from spreading online. The problems they addressed are only getting worse, making this kind of research just as important as ever. But Twitter decided to end free access to its API in February and launched paid tiers in March. The company said it was “looking at new ways to continue serving” academia but nevertheless started unceremoniously cutting off access to third-party users who didn’t pay. While the cutoff caused problems for many different kinds of users , including public transit agencies and emergency responders, academics are among the groups hit the hardest.
Researchers who’ve relied on Twitter for years tell The Verge they’ve had to stop using it. It’s just too expensive to pay for access to its API, which has reportedly skyrocketed to $42,000 a month or more for an enterprise account. Scientists have lost a key vantage point into human behavior as a result. And while they’re scrambling to find new sources, there’s no clear alternative yet.
Twitter gave researchers a way to observe people’s real reactions instead of having to ask study participants how they think they might react in certain scenarios. That’s been crucial for Pennycook’s research into strategies to prevent misinformation from fomenting online, for instance, by showing people content that asks them to think about accuracy before sharing a link.
Without being able to see what an individual actually tweets, researchers like Pennycook might be limited to asking someone in a survey what kind of content they would share on social media. “It’s basically hypothetical,” says Pennycook. “For tech companies who would actually be able to implement one of these interventions, they would not be impressed by that ... We had to do experiments somewhere to show that it actually can work in the wild.”
In April, a group of academics, journalists, and other researchers called the Coalition for Independent Technology Research sent a letter to Twitter asking it to help them maintain access. The coalition surveyed researchers and found that Twitter’s new restrictions jeopardized more than 250 different projects. It would also signal the end of at least 76 “long-term efforts,” the letter says, including code packages and tools. With enforcement of Twitter’s new policies somewhat haphazard (some users were kicked off the platform before others), the coalition set up a mutual aid effort. Scientists scrambled to harvest as much data as they could before losing their own access keys, and others offered to help them collect that data or donated their own access to Twitter’s API to researchers who lost it.
- Anti-harassment service Block Party leaves Twitter amid API changes
- Elon Musk’s lawyer accuses Microsoft of abusing its access to Twitter data
- Twitter backtracks, lets emergency and traffic alert accounts keep free API access
Twitter’s most affordable API tier, at $100 a month, would only allow third parties to collect 10,000 per month. That’s just 0.3 percent of what they previously had free access to in a single day, according to the letter. And even its “outrageously expensive” enterprise tier, the coalition argued, wasn’t enough to conduct some ambitious studies or maintain important tools.
One such tool is Botometer, a system that rates how likely it is that a Twitter account is a bot. While Musk has expressed skepticism of things like disinformation research, he’s actually used Botometer publicly — to estimate how many bots were on the platform during his attempt to get out of the deal he made to buy Twitter. Now, his move to charge for API access could bring on Botometer’s demise.
A notice on Botometer’s website says that the tool will probably stop working soon. “We are actively seeking solutions to keep this website alive and free for our users, which will involve training a new machine-learning model and working with Twitter’s new paid API plans,” it says. “Please note that even if it is feasible to build a new version of the Botometer website, it will have limited functionalities and quotas compared to the current version due to Twitter’s restricted API.”
The impending shutdown is a personal blow to Botometer co-creator Kai-Cheng Yang, a researcher studying misinformation and bots on social media who recently earned his PhD in informatics at Indiana University Bloomington. “My whole PhD, my whole career, is pretty much based on Twitter data right now. It’s likely that it’s no longer available for the future,” Yang tells The Verge . When asked how he might have to approach his work differently now, he says, “I’ve been asking myself that question constantly.”
“The platform went from one of the most transparent and accessible on the planet to truly bottom of the barrel.”
Other researchers are similarly nonplussed. “The platform went from one of the most transparent and accessible on the planet to truly bottom of the barrel,” says letter signatory Rebekah Tromble, director of the Institute for Data, Democracy, and Politics (IDDP) at George Washington University. Some of Tromble’s previous work, studying political conversations on Twitter, was actually funded by the company before it changed its API policies.
“Twitter’s API has been absolutely vital to the research that I’ve been doing for years now,” Tromble tells The Verge . And like Yang, she has to pivot in response to the platform’s new pricing schemes. “I’m simply not studying Twitter at the moment,” she says.
But there aren’t many other options for gathering bulk data from social media. While scraping data from a website without the use of an API is one option, it’s more tedious work and can be fraught with other risks. Twitter and other platforms have tried to curtail scraping, in part because it can be hard to discern whether it’s being done in the public interest or for malicious purposes like phishing.
Meanwhile, other social media giants have been even more restrictive than Twitter with API access, making it difficult to pivot to a different platform. And the restrictions seem to be getting tougher — last month, Reddit similarly announced that it would start to limit third-party access to its API.
“I just wonder if this is the beginning of companies now becoming less and less willing to have the API for data sharing,” says Hause Lin, a post-doctoral research fellow at MIT and the University of Regina developing ways to stop the spread of hate speech and misinformation online. “It seems like totally the landscape is changing, so we don’t know where it’s heading right now,” Lin tells The Verge .
There are signs that things could take an even sharper turn for the worse. Last week, inews reported that Twitter had told some researchers they would need to delete data they had already collected through its decahose, which provides a random sample of 10 percent of all the content on the platform unless they pay for an enterprise account that can run upwards of $42,000 a month. The move amounts to “the big data equivalent of book burning,” one unnamed academic who received the notice reportedly told inews .
The Verge was unable to verify that news with Twitter, which now routinely responds to inquiries from reporters with a poop emoji. None of the researchers The Verge spoke to had received such a notice, and it seems to so far be limited to users who previously paid to use the decahose (just one use of Twitter’s API that previously would have been free or low-cost for academics).
Both Tromble and Yang have used decahose for their work in the past. “Never before did Twitter ever come back to researchers and say that now the contract is over, you have to give up all the data,” Tromble says. “It’s a complete travesty. It will devastate a bunch of really important ongoing research projects.”
“We won’t be able to know as much about the world as we did before.”
Other academics similarly tell The Verge that Twitter’s reported push to make researchers “expunge all Twitter data stored and cached in your systems” without an enterprise subscription would be devastating. It could prevent students from completing work they’ve invested years into if they’re forced to delete the data before publishing their findings. Even if they’ve already published their work, access to the raw data is what allows other researchers to test the strength of the study by being able to replicate it.
“That’s really important for transparent science,” Yang says. “This is just a personal preference — I would probably go against Twitter’s policy and still share the data, make it available because I think science is more important in this case.”
Twitter was a great place for digital field experiments in part because it encouraged people from different backgrounds to meet in one place online. That’s different from Facebook or Mastodon, which tend to have more friction between social circles. This centralization sometimes fostered conflict — but to academics, it was valuable.
“If the research is not going to be as good, we won’t be able to know as much about the world as we did before,” Pennycook says. “And so maybe we’ll figure out a way to bridge that gap, but we haven’t figured it out yet.”
iPhone owners say the latest iOS update is resurfacing deleted nudes
Google opens up its smart home to everyone and will make google tvs home hubs, lego barad-dûr revealed: sauron’s dark tower from the lord of the rings is $460, someone finally made a heat pump that looks good inside your home, google i/o 2024: everything announced.
More from Science
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23935561/acastro_STK103__04.jpg "academic research api twitter")
Amazon — like SpaceX — claims the labor board is unconstitutional
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25288452/246992_AI_at_Work_REAL_COST_ECarter.png "academic research api twitter")
How much electricity does AI consume?
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25287681/1371856480.jpg "academic research api twitter")
A Big Tech-backed campaign to plant trees might have taken a wrong turn
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25287408/2003731596.jpg "academic research api twitter")
SpaceX successfully launches Odysseus in bid to return US to the lunar surface
DEV Community
Posted on Sep 29, 2021 • Updated on Feb 3, 2022
A comprehensive guide for using the Twitter API v2 with Tweepy in Python
Tweepy is a popular package in Python used by students, researchers and developers for interacting with the Twitter API. Recently, the version 4.0 of this package was released that supports the Twitter API v2 and the academic research product track. In this guide, we will learn how to use the various functionality available in the Twitter API v2, using Tweepy.
Note: At the time of writing this guide, the streaming endpoints in the Twitter API v2 (such as filtered stream and sampled stream) are not supported yet in Tweepy, but will be added in the future .
The complete documentation for Tweepy can be found here
Prerequisite
In order to work with the Twitter API, you need to have a developer account and your API keys and tokens to connect to the API. Learn more on how to obtain these keys and tokens here .
In order to work with Tweepy, make sure you have Python installed on your machine. Then, in the terminal run:
Note: If you already have Tweepy installed, you can upgrade it to the latest version i.e. 4.0 by running:
For all the examples in this section, you will first need to import the tweepy library, then you will need to initialize the client by passing it your bearer token. Once you have the client initialized, you will be ready to start using the various functions in this library.
1. Searching for Tweets from the last 7 days
In order to search Tweets from the last 7 days, you can use the search_recent_tweets function available in Tweepy. You will have to pass it a search query to specify the data that you are looking for. In the example below, we are searching for Tweets from the last days from the Twitter handle suhemparack and we are excluding retweets using -is:retweet .
By default, in your response, you will only get the Tweet ID and Tweet text for each Tweet. If you need additional Tweet fields such as context_annotations , created_at (the time the tweet was created) etc., you can specifiy those fields using the tweet_fields parameter, as shown in the example below. Learn more about available fields here . By default, a request returns 10 Tweets. If you want more than 10 Tweets per request, you can specify that using the max_results parameter. The maximum Tweets per request is 100.
Note: Not all Tweets have context_annotations associated with them, which is why, in the sample below, we only print the context_annotations if those are available for a Tweet.
2. Searching for Tweets from the full-archive of public Tweets
If you have access to the academic research product track , you can get Tweets older than 7 days i.e. from the full archive of publicly available Tweets. In order to get these Tweets, make sure to use the bearer token from an app connected to your academic project in the Twitter developer portal. You can use the search_all_tweets method and pass it the search query. As shown in the example above, you can also specify additional Tweet fields etc. that you'd like returned for your request to the Twitter API.
3. Getting Tweets from the full-archive of public Tweets for a specific time-frame
If you want to get Tweets from the full-archive for a specific time-period, you can specify the time-period using the start_time and end_time parameters, as shown in the example below:
4. Getting more than 100 Tweets at a time using paginator
As seen in the examples above, you can get upto 100 Tweets per request. If you need more than 100 Tweets, you will have to use the paginator and specify the limit i.e. the total number of Tweets that you want.
5. Writing Tweets to a text file
This example shows how you can write the Tweet IDs for each Tweet obtained for a search result, to a text file. Make sure to replace the file_name with the a name of your chosing. If you wish to write other fields to the text file, make sure to adjust the script below accordingly.
6. Getting Tweets with user information, for each Tweet
In the examples so far, we have seen how to get Tweet information for the Tweets that we have searched for. However, if you need additional information associated with the Tweet, such as the information of the user Tweeting it, you can use expansions and pass it to the search_recent_tweets function.
In this example, we want user information, which is why the value for expansions that we pass is author_id . Additionally, we will specify the user_fields that we want returned such as profile_image_url etc. Learn more about available fields here .
From the response, we will get the users list from the includes object. Then, we will look up the user information for each Tweet, using the author_id of the Tweet.
7. Getting Tweets with media information, for each Tweet
In this example, we want media information, which is why the value for expansions that we pass is attachments.media_keys . Additionally, we will specify the media_fields that we want returned such as preview_image_url etc. Learn more about available fields here .
From the response, we will get the media list from the includes object. Then, we will look up the media information for each Tweet, using the media_keys from the attachements for the Tweet.
8. Searching for geo-tagged Tweets
Some Tweets have geographic information associated with them. The search endpoints in the Twitter API v2 support operators such as place , place_country , bounding_box , point_radius etc. (these operators are currently only available in the academic research product track) that allow you to get these geo-tagged Tweets.
In the example below, we want all Tweets that are from the country US , which is why we specify it in our search query using the place_country:US operator. Now because by default, only the Tweet ID and Tweet text are returned, we have to specify the fact that we want the geo information in our response as well. We do this by passing the expansions='geo.place_id' to the search_all_tweets function and we also specify the geo fields that we are looking for using place_fields=['place_type','geo'] .
In our response, we get the list of places from the includes object, and we match on the place_id to get the relevant geo information associated with the Tweet (the place.full_name in the example below)
9. Getting Tweet counts (volume) for a search query
So far, we have seen examples of how to get Tweets for a search query. However, if you want to get the count of Tweets (volume) for a search term, you can use the get_recent_tweets_count function. You can pass it the search query and specify the granularity for the data aggregation e.g. if you want the daily count, hourly count or 15-minute count for a search term.
The response will look something like this:
10. Getting a user's timeline
In order to get the most recent 3200 Tweets from a user's timeline, we can use the get_users_tweets method and pass it the user id. We can also specify additional fields that we want using the tweet_fields and expansions (as shown in the examples above).
11. Getting a user's mentions
In order to get the most recent 3200 mentions for a user, we can use the get_users_mentions method and pass it the user id. We can also specify additional fields that we want using the tweet_fields and expansions (as shown in the examples above).
12. Getting a user's followers
In order to get the followers of a user, we can use the get_users_followers function and pass it the user ID. If we want additional fields for the User object such as profile_image_url , we can specify those using the user_fields parameter.
13. Getting users that a user follows
In order to get the list of users that a user follows, we can use the get_users_following function and pass it the user ID. If we want additional fields for the User object such as profile_image_url , we can specify those using the user_fields parameter.
14. Getting users that like a Tweet
In order to get the list of users that like a Tweet, we can use the get_liking_users function and pass it the Tweet ID. If we want additional fields for the User object such as profile_image_url , we can specify those using the user_fields parameter.
15. Getting users that retweeted a Tweet
In order to get the list of users that retweeted a Tweet, we can use the get_retweeters function and pass it the Tweet ID. If we want additional fields for the User object such as profile_image_url , we can specify those using the user_fields parameter.
16. Getting Tweets that a user liked
In order to get the list of Tweets that a user liked, we can use the get_liked_tweets function and pass it the User ID. If we want additional fields for the Tweet object such as context_annotations , created_at etc. we can specify those using the tweet_fields parameter.
17. Lookup Tweets using Tweet IDs
In some cases, if we have a list of Tweet IDs and want to build the Tweet dataset for these Tweet IDs, we can use the get_tweets function and pass it the list of Tweet IDs. By default, only the Tweet ID and Tweet text are returned. If we want additional Tweet fields, we can specify those using tweet_fields parameter.
18. Lookup Users using User IDs
In some cases, if we have a list of User IDs and want to build the User dataset for these User IDs, we can use the get_users function and pass it the list of User IDs. If we want additional User fields, we can specify those using user_fields parameter.
19. Create a Tweet
If you want to create a Tweet with Tweepy using the Twitter API v2, you will need to make sure that you have your consumer key and consumer secret, along with your access token and access token secret, that are created with Read and Write permissions. You will use these keys and token when initializing the client as shown below.
20. Retweet a Tweet
If you want to retweet a Tweet with Tweepy using the Twitter API v2, you will need to make sure that you have your consumer key and consumer secret, along with your access token and access token secret, that are created with Read and Write permissions (similar to the previous example). You will use these keys and token when initializing the client as shown below.
21. Replying to a Tweet
If you want to reply to a Tweet with Tweepy using the Twitter API v2, in the create_tweet method, you can simply pass the in_reply_to_tweet_id with the ID of the Tweet that you want to reply to, as shown below:
These are some common examples of working with the Twitter API v2 using Tweepy. As Tweepy adds support for additional endpoints, we will update this post to include examples of using those endpoints.
If you have any questions or feedback about this guide, please feel free to reach out to me on Twitter !
Also, special shoutout to Harmon and the contributors of the Tweepy package for supporting the Twitter API v2 and the academic product track.
Top comments (13)
Templates let you quickly answer FAQs or store snippets for re-use.
- Location Italy
- Work Software Engineering at Verona
- Joined Dec 10, 2019
Great tutorial. Thanks. I have to do something similar. I have to extract both retweet and comments/replies done by a specific user in input(or list) in a specific page/user that contains a specific hashtag. For retweet no problem. For comments some
- Joined Dec 15, 2021
great tutorial. I am glad you used tweepy to show the functionalities! Thank You
- I was not able to execute some statements because I do not have access to the academic research account
- I was not able to complete # 9. Getting Tweet counts (volume) for a search query because It says , "unexpected parameter: granularity".
- Joined Jan 7, 2022
Great tutorial.
- Joined Feb 9, 2023
Hey man. Thank you so much for this article. I was stuck with a problem for 7 days, but it's solved now. I still have one small problem though, and i think you can help me out. Is there any ways to contact you? Would you mind adding me on telegram? Username: everydaypsychologies
or write me an email at: [email protected]
Best regards Mikkel
- Location Gdańsk, Poland
- Joined Sep 29, 2019
I get this error and I have no idea why, in other project that uses Twitter API v1 every works fine: tweepy.errors.Unauthorized: 401 Unauthorized
- Joined Jun 13, 2022
So I have streaming working for V2. However, it seems that the only data I can get for the author of the incoming tweets is the author_id.
Does this mean I have to do a separate user lookup to get username, description, etc... using the following?
users = client.get_users(ids=idarray, user_fields=fieldarray)
Also, I see there is an allowance of 900 calls per 15 minutes. However, when I run the following function, 'data = api.rate_limit_status()', I can't see any of my calls being decremented.
- Joined Nov 25, 2021
two questions: 1 - How can I reply to tweets? 2 - How can I tweet an image?
- Joined Dec 13, 2021
If I want to search for a given topic or for tweets that have above x likes how would I do that?
Thanks this guide has been uber helpful
- Joined Mar 16, 2022
Thanks for the great post. How can I retrieve all the replies for a given tweet ?
- Joined Mar 20, 2022
Hey, This is really helpful. Is there any update on Filtered Stream in Python in a similar way ? @TwitterDev
- Joined Jul 29, 2022
i needed this. thank you.
- Joined Nov 30, 2021
How to add language filter when using pagination?
- Location Nairobi
- Work Learning Data Science
- Joined Jan 2, 2020
Hey @suhemparack How can I tweet an image?
Are you sure you want to hide this comment? It will become hidden in your post, but will still be visible via the comment's permalink .
Hide child comments as well
For further actions, you may consider blocking this person and/or reporting abuse

Why we use API in mobile application development?
Algosoft Apps Technologies - Mar 11

Code a 2-layer Neural Network from Scratch
HoangNg - Apr 9

Sending out SMS messages via Twilio
Ida Delphine - Mar 10

Why I think Python is a Great first Language
Jima Victor - Apr 13

We're a place where coders share, stay up-to-date and grow their careers.
Academic Research with the Twitter API v2
Suhem Parack, Developer Advocate for Academic Research at Twitter, discusses how to do academic research with the Twitter API v2. He delves into the different kinds of data available on the Twitter API, some code samples, examples of research done with the Twitter API, and resources available for academics using this platform.
Author: Suhem Parack,
Duration: 1:00:49
- Join our Mailing List
- Privacy Policy
- Terms and Conditions

Twitter’s API access changes could mark ‘end of an era’ in academic research on the platform
Feb 2, 2023

In a Feb. 1 tweet, Twitter announced that it will soon no longer support free access to the social media platform’s application programming interface (API), which allows developers and researchers, including those at the University of Washington’s Center for an Informed Public and peers at other universities and research centers, to collect and analyze Twitter data.
While Twitter’s tweet about API access indicated that details about pricing would be forthcoming, the future of continued academic research on the platform is very much in question.
“This could very well be the end of an era for platform transparency and social media research,” said Center for an Informed Public director Kate Starbird , a UW Human Centered Design & Engineering associate professor.
In a Mastodon thread on Thursday, Starbird noted that, while studying “crisis informatics” as a PhD student, she built her first Twitter collection script in 2010 in the wake of the Haiti earthquake. Since then much of her work has focused on studying how information about crisis events, including the 2010 Deepwater Horizon oil spill , 2013 Boston Marathon bombing , the Syrian Civil War , and the 2018 Hawaii false missile alert , travels and spreads via the platform.
In recent years, CIP researchers, including Starbird, have focused much of their attention studying how rumors, conspiracy theories, mis- and disinformation about voting in U.S. elections emerged, traveled and spread on Twitter, work that has led to peer-reviewed research in academic journals like the Journal of Quantitative Description: Digital Media and Nature Human Behaviour and citations in the final report from the U.S. House Select Committee to Investigate the January 6th Attack on the U.S. Capitol .
As Justin Hendrix wrote in Tech Policy Press last year , the CIP’s research and Twitter data-collection efforts around the 2020 U.S. elections will “serve as a substantial building block for years of future research on phenomena at the intersection of social media, politics, and democracy.”
As researchers await more details about Twitter API pricing, what might come next?
“It’s long been time (for my team, at least) to move on,” Starbird wrote on Mastodon, noting that this “will profoundly change how researchers (and society) can study and understand online behavior.”
Depending on pricing for academic access, researchers at the Center for an Informed Public may be able to continue research on Twitter, albeit “to a much smaller extent,” Starbird said, adding that “the under-resourced PhD student won’t have a chance to work in this environment. As a wide-eyed PhD student on a ‘crisis informatics’ team, in the wake of the Haiti Earthquake, I built an infrastructure to support crisis mapping during disaster events. That kind of emergent ‘action research’ won’t be possible.”
Since January 2020, research infrastructure at the UW Center for an Informed Public has collected about 2 billion tweets, including narratives around COVID-19, vaccines and elections.
PHOTO ABOVE: Twitter’s San Francisco headquarters by Dale Cruse via Flickr / CC BY 2.0
Share this:
- Click to share on Facebook (Opens in new window)
- Click to share on Twitter (Opens in new window)
- Click to share on LinkedIn (Opens in new window)
Survivor-informed research surrounding online discourses of abuse
May 15, 2024
A team of CIP researchers is currently pursuing research that seeks to understand the impacts of social media narratives surrounding the 2022 Depp v. Heard defamation trial.

Examining mischaracterizations of voter registration data in Washington state
May 14, 2024
There are often many explanations for why patterns and outliers occur in a dataset.

Media literacy coalition in California brings MisinfoDay, first developed in Washington state, to the Golden State
May 9, 2024
Inspired by the annual MisinfoDay in Washington state, a local media literacy coalition in Monterey County, California adapted the educational program to host the first MisinfoDay in the Golden State on May 7.

- Documentation
Twitter Academic API
Hi, I am here to help my friends to ask some questions about applying for an academic API.
would anyone know how to apply for an academic API after twitter’s announcement of charging fees? what kind of materials are needed to prepare for application in the current situation? And will it charge some fees? Thank you!
There’s some advice here Twitter Developer Access - twarc but be aware that they’ve not been approving any accounts recently judging by all the other posts about not hearing back after applying
Thanks! Do we need to pay fees if we apply for an academic API now?
Currently no, but there was suggestion of $100 per month but they never clarified or followed up with that. There is also Enterprise which is rumoured to cost at least $42,000 per month too. But again, nothing was launched or made clear.
hi all, I had an academic API, and has been away for 7 months, now I see it has been removed from my profile. What is the fastest way to gain it? The new application looks scary. Thanks
You won’t get it. All Academic accounts have been “downgraded” to Elevated and now, we have nothing. Everything is on hold.
oh I see. I saw the price page. If I want to read ~3000 tweets per day, how much I need to pay? Also is everything on hold is a good thing?! can we be optimistic they may ease that? I saw academic application form, although it does not open the link but it becomes very very complicated, like writing a big proposal for them? does anyone applied for it recently?
For 3000 tweets per day, so 90000 tweets per months you still need Pro, so USD5000 per month… I have no idea about the academic access to be honest with you…but there is no discussion, nor announcement about it lately.
Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
academictwitteR: Access the Twitter Academic Research Product Track V2 API Endpoint
Package to query the Twitter Academic Research Product Track, providing access to full-archive search and other v2 API endpoints. Functions are written with academic research in mind. They provide flexibility in how the user wishes to store collected data, and encourage regular storage of data to mitigate loss when collecting large volumes of tweets. They also provide workarounds to manage and reshape the format in which data is provided on the client side.
Documentation:
Please use the canonical form https://CRAN.R-project.org/package=academictwitteR to link to this page.
Pro-Palestinian posts significantly outnumbered pro-Israeli posts on TikTok, new Northeastern research shows
- Search Search
The pattern of pro-Palesitinian posts is consistent with a prolonged social movement, the research suggests, while the pattern of pro-Israeli posts is typical of what follows a major news event.
- Copy Link Link Copied!

With millions of users across the globe, including the Middle East, TikTok has become a popular source of information and commentary on the Israel-Hamas war.
But pro-Palestinian posts to the social media app significantly outnumber pro-Israeli posts and follow a very different pattern, new research from Northeastern University reveals.
The pattern of pro-Palestinian posts is consistent with a prolonged social movement, the research suggests, while the pattern of pro-Israeli posts is typical of what follows a major news event.
The number of pro-Israeli content posted to TikTok has steadily declined since Hamas’ Oct. 7 attack on Israel, the research shows.
“There’s a lot of posting activity initially, and then there’s a gradual decline over time,” says Laura Edelson, an assistant professor at Northeastern’s Khoury College of Computer Sciences.
Northeastern Global News, in your inbox.
Sign up for NGN’s daily newsletter for news, discovery and analysis from around the world.
The opposite has happened with pro-Palestinian content.
“What we see with pro-Palestine posting activity — it grows organically over time, it culminates and then it has a symmetric decline,” says Edelson, a computer scientist who studies large online platforms. “That’s the kind of pattern that is more commonly associated with social movements.”
Edelson was granted access to the TikTok Research API , which allows independent and academic researchers who work for nonprofit institutions to access certain data to support their work.
She collected data on more than 280,000 TikTok posts from the United States that had specific hashtags related to the Israel-Hamas war. Examples include political statements such as #IStandWithIsrael or #SavePalestine, as well as more general apolitical tags like #Gaza or #Israel.
The data was gathered from 12 three-day windows — beginning Oct. 7 to Oct. 9, 2023, and ending Jan. 26 to Jan. 29, 2024.
Edelson examined the data in three major ways.
First was the number of posts. There were 170,430 pro-Palestinian posts, 8,843 pro-Israeli posts and 101,706 neutral or general posts.
Edelson also looked at the posts’ page views — there were 236 million views for pro-Palestinian posts, 14 million for pro-Israeli posts and 492 million views for neutral or general posts.
Finally, Edelson compared whether the number of posts and the post views were proportionate — this enabled Edelson to conclude whether TikTok was amplifying certain types of posts.
“It’s not enough to look at content,” Edelson says. “Big differences in how people experience content come from differences in amplification too.”
Content was amplified on both sides, the research suggests.
“There’s periods of time when TikTok is disproportionately amplifying pro-Palestine content, and there’s times when it’s disproportionately amplifying pro-Israel content,” Edelson says. “When you sum up everything over the entire study period, they amplify those two things equally, but it changes over time, initially.”
Featured Stories

Researchers are translating ‘whale-speak’ — accents included — and this Northeastern network scientist is leading the way

This former cheerleader is aiming to be a ‘world-class star’ in hammer throw

‘Challengers’ is where tennis meets love. But what happens in real life if you date someone in your field?

What are vampire facials? Do they work? And what went wrong in the procedures linked to HIV?
Edelson thus divides the data into three “phases.” In the first phase, the 3½ weeks following the Oct. 7 Hamas attack, neutral or general content is both most posted and most seen.
Edelson says the high number of general posts and views per general post is “fairly similar” to what happens on the platform following any major news event. She notes that TikTok is unique among social media platforms. Rather than amplifying the most extreme voices, it is “majoritarian,” she says.
“TikTok wants to find the most popular thing and then show that most popular thing as widely as possible,” Edelson says.
She also notes that neutral or general content is predominantly higher in quality — in terms of production value — which means it is more likely to be amplified by TikTok.
Pro-Israeli content follows the same pattern as general news: it is highest in this phase as well, but it steadily declines after the first week.
Pro-Palestinian content, on the other hand, jumps significantly in the second week and continues to grow steadily.
But things begin to change on Oct. 27 when the number page views on pro-Israel posts skyrockets — 2,555 views per post compared to 336 views per post previously.
Edelson says she doesn’t know why this occurred. But it lasts through the return of some Israeli hostages during a ceasefire that began Nov. 24 and into the first half of December.
The final phase begins on Dec. 15 when views per post for all categories fall dramatically.
“Interest in topics declines over time, that’s very normal,” Edelson says. “But the speed of the fall off is striking and not well explained by other events.”

Recent Stories

COMMENTS
Learn the fundamentals of using X data for academic research with tailored get-started guides. Or, take your current use of the API further with tutorials, code samples, and tools. Curated datasets. Free, no-code datasets are intended to make it easier for academics to study topics that are of frequent interest to the research community.
We will only be using the new Twitter API v2 and not the old API (v1.1). To learn more about the Twitter API v2, check out this technical overview of the Twitter API v2. Let us start with module 1, that provides an introduction to Twitter API and examples of research with it.
Announcements. suhemparack January 26, 2021, 7:02pm 1. Today, we launched a product track on our new API tailored to serve the needs of the academic research community doing research with Twitter data. This post provides a technical overview of what's available in this Academic Research product track, and how you can get started using it.
At the end of 2020, Twitter introduced a new Twitter API built from the ground up. Twitter API v2 comes with more features and data you can pull and analyze, new endpoints, and a lot of functionalities. With the introduction of that new API, Twitter also introduced a new powerful free product for academics: The Academic Research product track.
The functionality available within Twitter API v2 is in development and serves adequate access for the majority of developers on the platform. While elevated levels of access are coming soon, developers in need of higher levels of access can explore our the standard v1.1, premium v1.1, and enterprise APIs. For more detail about our plans for ...
Academic Research Product Track. Launched in January 2021, the academic research product track is one of the biggest updates to the Twitter API v2 for the academic research community. It provides qualified academic researchers free access to the full-archive of public Tweets (previously, academics had to use the paid premium API to get Tweets ...
Getting started with the Twitter API v2 for academic research. Welcome to this '101 course' on getting started with academic research using the Twitter API. The objective of this course is to help academic researchers learn how to get Twitter data using Twitter API v2. By the end of this course, you will learn: What the Twitter API is
In the context of research, Twitter data refers to the public information that is provided via Twitter's application programming interface (API). The API supports various endpoints such as recent search, filtered steam etc. that let developers and researchers connect to the API and request Twitter data.
Academic researchers have been taking advantage of the Twitter API since its first introduction in 2006 and have used the data to study a variety of topics, Twitter says, like state-backed efforts ...
Suhem Parack, Developer Advocate for Academic Research at Twitter, discusses how to do academic research with the Twitter API v2. He delves into the differen...
Twitter's most affordable API tier, at $100 a month, would only allow third parties to collect 10,000 per month. That's just 0.3 percent of what they previously had free access to in a single ...
Tweepy is a popular package in Python used by students, researchers and developers for interacting with the Twitter API. Recently, the version 4.0 of this package was released that supports the Twitter API v2 and the academic research product track. In this guide, we will learn how to use the various functionality available in the Twitter API v2, using Tweepy.
Suhem Parack, Developer Advocate for Academic Research at Twitter, discusses how to do academic research with the Twitter API v2. He delves into the different kinds of data available on the Twitter API, some code samples, examples of research done with the Twitter API, and resources available for academics using this platform. Author: Suhem Parack,
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window.
In a Feb. 1 tweet, Twitter announced that it will soon no longer support free access to the social media platform's application programming interface (API), which allows developers and researchers, including those at the University of Washington's Center for an Informed Public and peers at other universities and research centers, to collect and analyze Twitter data.
Twitter Academic API - Academic Research - X Developers. academic-research, api, twitter-api. sihaoch March 18, 2023, 1:01am 1. Hi, I am here to help my friends to ask some questions about applying for an academic API. would anyone know how to apply for an academic API after twitter's announcement of charging fees? what kind of materials are ...
In October 2020, Twitter opened a new academic track in beta and the API was fully opened for public research in January 2021. The new version of the free, academic API allowed for more precise queries. Researchers could add up to 1,000 rules when using the filter stream, compared to 25 query rules in the standard API.
In order to get Tweets for your research using the Twitter API, you need to specify what Tweets you are looking for. To do so, you need to write a search query (when using search endpoints) or set rules (when using the filtered stream endpoint).
Package to query the Twitter Academic Research Product Track, providing access to full-archive search and other v2 API endpoints. Functions are written with academic research in mind. They provide flexibility in how the user wishes to store collected data, and encourage regular storage of data to mitigate loss when collecting large volumes of tweets. They also provide workarounds to manage and ...
Edelson was granted access to the TikTok Research API, which allows independent and academic researchers who work for nonprofit institutions to access certain data to support their work. She collected data on more than 280,000 TikTok posts from the United States that had specific hashtags related to the Israel-Hamas war.
より正確で網羅された無作為のデータを公共の会話から無料で入手しましょう。. この専用アクセスを使うと、すべてのX API v2エンドポイントへのアクセス、月あたりに収集可能なツイート上限の引き上げ、研究用に強化された機能へのアクセスが可能になり ...